Doyup Lee, Anomaly Detection in Multivariate Non-stationary Time Series for Automatic DBMS Diagnosis, ICMLA, 2017를 간단하게 요약, 리뷰한 글입니다. 개인적인 공부용으로 작성하여 편한 어투로 작성한 점 양해바랍니다.
1. Introduction
- data scale 이 커지면서 DBMS 가 Big Data application 에서 중요한 부분을 담당하게 되었다.
- DBMS 에서 anomaly detection 을 하는 것은 다음 2 가지 관점에서 중요하다.
- DBMS 가 다운되거나, low performance 를 보이는 상황을 예방할 수 있다.
- DBA 가 DBMS 를 사용할 때, configuration 이나 SQL 문의 tuning point 를 찾아내는 데 도움된다.
- “Anomaly” 의 정의
- data 마다, domain 마다 다르게 정의할 수 있지만, 여기서는 time series data 에서 예측할 수 없는 변화가 일어난 것을 anomaly 라고 정의한다.
- 급격한 변화가 일어났더라도 과거 정보로부터 예측할 수 있었다면 anomaly 로 보지 않겠다.
- data 마다, domain 마다 다르게 정의할 수 있지만, 여기서는 time series data 에서 예측할 수 없는 변화가 일어난 것을 anomaly 라고 정의한다.
- Anomaly detection 은 labeled data 를 구하는 비용이 크고, 구하더라도 data 의 양이 적어 supervised ML 로 구현하기 힘들다.
- domain expert 에게 큰 비용을 지불하더라도, 장 시간의 data 를 보고 소수의 anomaly 를 labeling 하는 것은 사람이 하기에는 거의 불가능한 일이다.
- 본 논문에서는 non-stationary time series data in DBMS 를 가지고 autoencoder 를 통해 reconstruction error 로 anomaly detection 을 하는 model 을 제안하겠다. anomaly 를 포함한 time period 를 detect 하고, 그 원인이 되는 causal event 를 찾는 것이 목적이다.
2. Theoritical Background
2.1. Anomaly Detection
- 생략
2.2. Deep Autoencoder
- 생략
2.3. Statistical Process Control
- Statistical Process Control (SPC) 는 어떤 process 의 output 을 모니터링하기 위한 statistical model 이다.
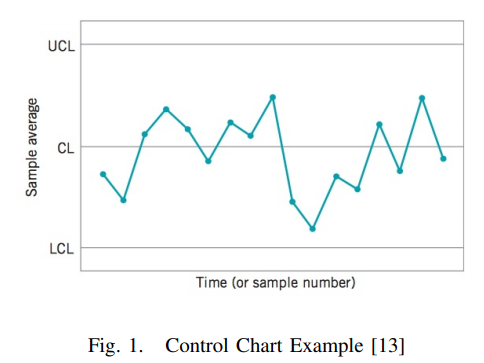
- 위 그림에서 평균을 CL 로,
CL + 3*sigma를 UCL(upper control limit)로,CL - 3*sigma를 LCL(lower control limit)로 잡은 뒤, LCL ~ UCL 범위 밖에 point 가 나타나면 문제가 생겼다고 판단하는 model - reconstruction error based anomaly detection model 은 적절한 threshold 를 설정하기 어렵다는 약점을 SPC 를 통해 보완할 수 있을 것이다.
- anomaly threshold 를 process control 관점에서의 통계적 background 를 통해 설정할 것이다.
2.4. Non-stationary Time Series
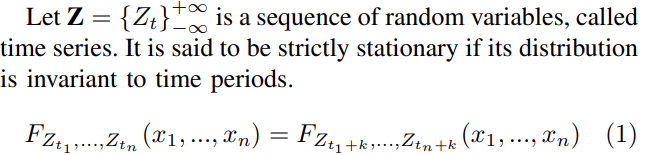
- time series r.v.
Z에 대해,Z가 strictly stationary 하다의 정의는 Z 의 distribution 이 time period 에 invariant 한 것을 말한다.- 하지만, 당연히 real world data 에서는 stationary time series 는 찾아보기 힘들며, 대신 1st moment 와 2nd moment 가 time period 에 invariant 한 경우 weakly stationary 라고 부른다.
- non-stationary time series data 는 time period 마다 다른 distribution 을 가진다고 볼 수 있기에, mean 과 variance 가 time-varying 하며, input data 를 여러 개의 sliding window 로 자른 각각의 time window 들을 같은 distribution 에서 sampling 된 data 라고 볼 수 없다.
- If input data has non-stationarity, the model tries to learn different input distribution as input changes and eventually fails to learn successfully
- input data (각 sliding window) 가 ideal 한 distribution 에서 independent 하게 sampling 된 것이라고 생각하고, 해당 distribution 을 근사하는 Deep Learning model 들은 정상적으로 학습할 수 없게 된다.
- 따라서, non-stationary time series data 를 stationary time series data 로 변환시킨 후에 model 을 학습시켜야 한다.
- 본 논문에서는 이렇게 transformation 하는 layer 를 추가할 것이고, 이를 Batch Temporal Normalization layer 라고 부른다.
3. Proposed Model
3.1. Problem Description
- DBMS 장애 발생 및 해결 과정의 일반적인 시나리오
- DBMS 에 어떤 장애가 발생한 경우, 일반 사용자는 DB consultant 를 불러 장애가 발생한 시간과 이벤트를 찾아달라고 요청한다.
- DB consultant 는 원인을 찾아낸 뒤, DBMS configuration 을 변경하거나 wrong SQL 문을 tuning 해서 해결한다.
- 이 과정에서 consultant 는 본인의 과거 경험과 지식을 통해 여러 원인을 찾아보는 수동 작업을 거치게 된다.
- DBMS 관련 event metric 과 log 는 초단위로 쌓이기 때문에, 에러가 발생한 시간을 정확히 찾고, 그로부터 원인까지 분석하기에는 너무나 많은 시간이 소요된다.
- configuration 변경 혹은 SQL tuning 등은 DBA 의 domain 지식이 필요한 일일지라도, 장애 발생 시간과 원인이 되는 event 를 찾아내는 것은 DBMS metric 을 통해 자동화할 수 있을 것이다.
- 본 논문에서 다루고자 하는 problem 이 바로 이것이다.
- anomaly 가 발생한 time period 를 자동으로 진단하고, 그 anomaly 와 연관된 causal event 를 찾아내는 것
3.2. Data
- data 는 1 분 단위로 수집
- 1) DBMS stat Metrics
- DBA 의 자문을 받아 장애 발생 분석에 가장 중요한 6 개의 main stat metric 만 사용했다.
- Cpu Used
- Active Session
- SQL 을 execute 하는 session 수
- Session Logical Reads
- query 의 execution 을 위한 requested block 수
- Physical Reads
- disk 가 읽은 block 수
- Execute Counts
- SQL execution 의 수
- Lock Waiting Session
- lock 상태에서 기다리고 있는 session 수
- DBA 의 자문을 받아 장애 발생 분석에 가장 중요한 6 개의 main stat metric 만 사용했다.
- 2) DBMS events Metrics
- DB session 이 query 를 날렸을 때, 발생하는 event 들에 대한 metric
- direct path read
- SQL net message from client
- LGWR wait for redo copy
- 등등
- 이러한 metirc 은 DB 에 장애가 특정 시점에 발생했을 때, 원인을 찾는데 사용됨
- DB session 이 query 를 날렸을 때, 발생하는 event 들에 대한 metric
3.3. Model Scheme
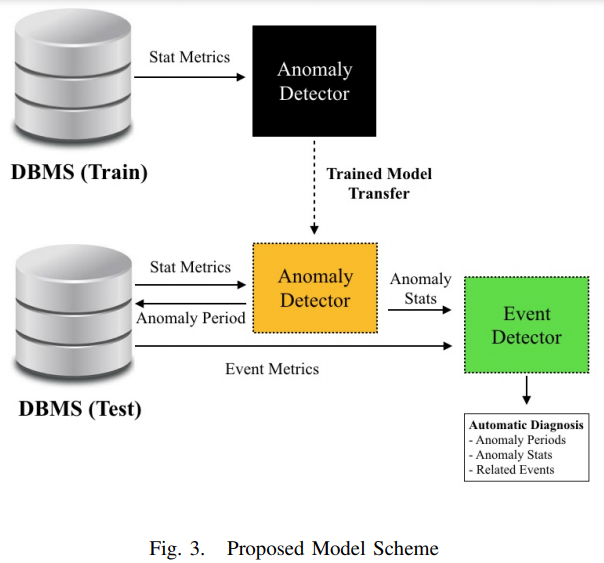
- DBMS stat metric 으로부터 anomaly 가 발생한 time period 를 출력하는 anomaly detector 를 학습
- 이 모델을 바탕으로 test 환경에 맞춰 transfer learning 을 한 model 을 사용해 나온 anomaly period 의 event metric 을 통해 원인을 찾아 DB user 를 위한 리포트를 제공하는 event detector 를 따로 둠
3.4. Anomaly Detector Model Description
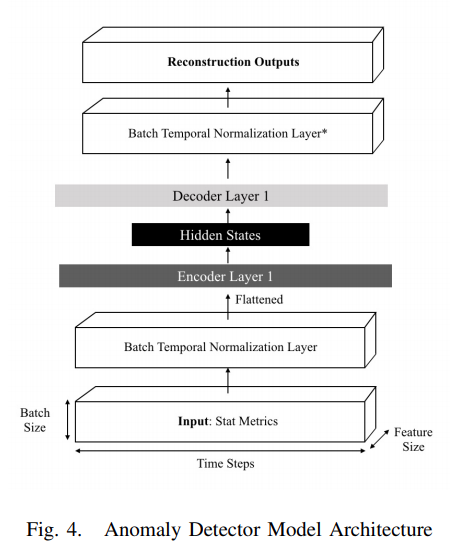
- reconstruction error 기준으로 anomaly 판별하는 autoencoder
- 3 hidden layer autoencoder 이며, input data 를 stationary time series 로 변환하기 위한 Batch Temporal Nomralization Layer 존재
3.5. Batch Temporal Nomralization
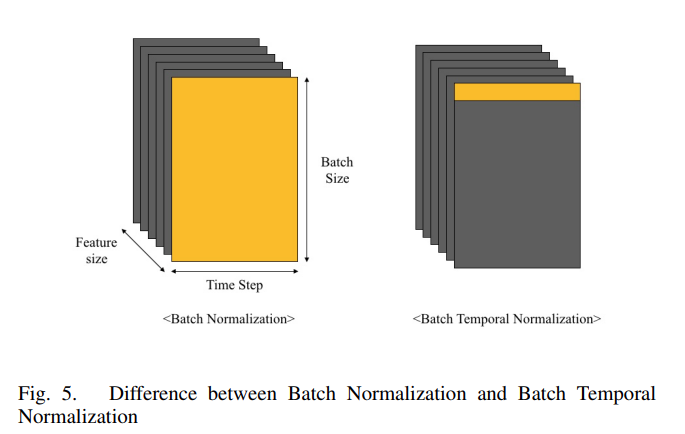
- input 으로 들어오는 time series data 에 stationarity 를 부여하기 위한 layer
- normalization 을 feature scale 단위로 하는 것이 아니라, time period 단위로 하는 것
- 위 그림의 노란 부분이 각 layer 에서 normalization 하는 범위
- 즉, BTN layer 는 각 input sample 이 time period 의 선택에 상관없이 같은 mean, std 를 갖도록 만드는 layer
3.6. Anomaly Period Detection with SPC
- reconstruction error 기반의 anomaly score 에 SPC 를 적용한 threshold 를 기준으로 anomaly 가 포함된 구간임을 판단
4. Experiments
4.1. Training Results of Deep Autoencoder
- autoencoder model 의 hyperparameter 들은 반복 테스트를 통해 선택
- adam optimizer
- 0.001 learning rate
- 1500 batch size
- data
- 1 분 단위로 한 달 동안 수집한 DBMS stat metric 6 column
- train:valid:test = 6:2:2
- whole data 로 정규화
- time window 크기는 30 : 30 분
- 즉, 30 분 구간 안에 anomaly 가 있는지를 판단하게 됨
- activation ft : ReLU
- time series data 를 다룰 때는 sigmoid 보다 ReLU 를 많이 사용함
- train loss : MSE
- 1 분 단위로 한 달 동안 수집한 DBMS stat metric 6 column
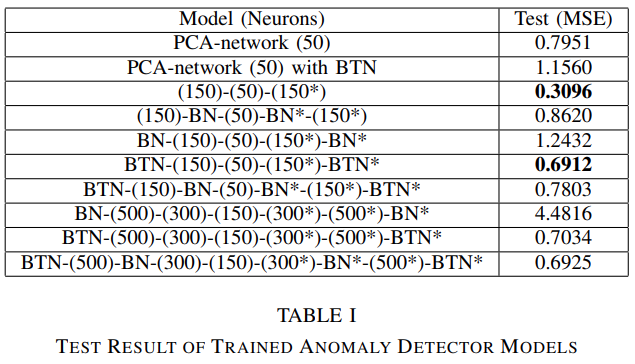
- hidden layer, unit 선택은 아래 표와 같이 여러 가지 network 를 모두 테스트해본 뒤, test loss 와 anomaly detecting performance 를 고려해서 선택
- test loss 만 기준으로 했을 때는, BTN layer 가 없는 model 이 best 였지만, anomaly detecting performance 까지 고려했을 때는 BTN-(150)-(50)-(150)-(BTN) layer 가 best 였음
4.2. Anomaly Periods Detection
- anomaly period detection performance test 는 train data 를 얻은 DBMS 가 아닌, 다른 DBMS 환경에서 수행
- DBA 가 진단한 과거 DBMS 장애 data 를 사용하여 validation check
- 10 가지 장애 case(상황)에 대해서 test 를 수행하였으며
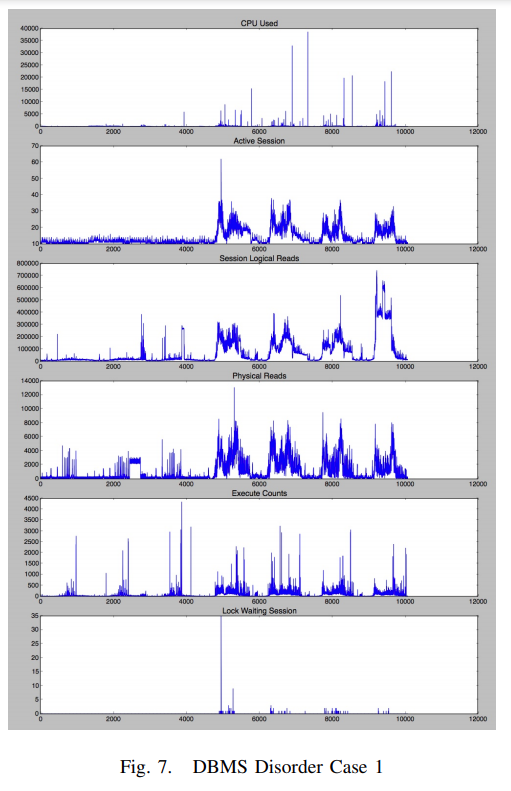
- figure7 은 장애 case I 에서 stat metric 그래프
- DBA 는 2번째 그래프인 active session stat 을 보고, active session 이 peak 로 튀는 지점을 disorder period 로 판단
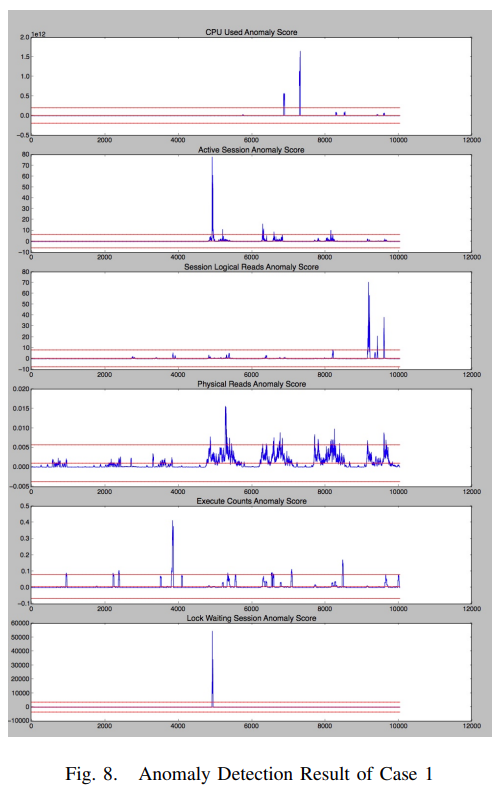
- figure8 은 장애 case I 에서 anomaly score 그래프
- anomaly detector 는 각 stat 에서 UCL 선 위의 period 를 모두 disorder period 로 판단
- 이 경우 DBA 가 판단한 period 를 포함해서 10 개 정도의 period 를 detecting
- DBA 가 판단한 period 가 가장 anomaly score 가 높은 결과가 나옴
- anomaly detector 는 각 stat 에서 UCL 선 위의 period 를 모두 disorder period 로 판단
- figure7 은 장애 case I 에서 stat metric 그래프
- BTN 이 없는 model 과 있는 model 을 비교해봤을 때, BTN 이 있는 model 이 더 합리적인 결과가 나왔음
- UCL 을 threshold 삼은 anomaly detector 는 anomaly period 후보를 DBA 에게 제공해주는 것으로 활용할 수 있음
- DBA 가 진짜 disorder period 라고 보는 것보다는 살짝 보수적으로 candidate 을 여러 개 건네주면, DBA 가 더 자세히 살펴보는 형태로 detecting time 을 줄여주는 형태로 활용 가능
4.3. Causal Events Detection
- anomaly 가 발생한 period 를 찾더라도 causal event 를 찾아내는 것이 중요한데, DBA 가 그 원인을 찾고 해결하는 데도 시간이 오래 걸리기 때문
- Time series distance/similarity measure 를 활용해서 causal event 를 찾을 수 있음
- DTW (Dynamic Time Wraping)
- Pearson correlation
- 해당 anomaly period 의 stat metric 과 가장 밀접한 event 를 찾아내는 데 활용
- 논문에 적힌 내용은 해당 data 에 specific 한 내용인 것 같아 생략
5. Conclusion and Future Work
- DBMS diagnosis 를 자동화하기 위한 ML model 제안
- autoencoder 기반한 reconstruction error 로 anomaly period 를 detecting
- non-stationary multivariate time series 를 처리하기 위한 BTN layer 제안
- 실험해보니 더 좋은 성능을 보였다라는 주장
- threshold 를 정하기 위한 방법으로 SPC approach 방식 적용
- 전통적인 SPC 에서 사용하던 대로 3 sigma 를 기준으로 UCL 을 정했지만, 이건 사용 목적과 data 에 따라 다르게 선택해도 무방
- DBA 가 anomaly period 와 causal event 를 찾는 시간을 줄여주기 위함
- 발전 가능성
- RNN, CNN layer 를 추가해서 sequential and local relationship 을 hidden layer 에서 유지할 수 있는 방안
- pre-trained model 을 기반으로 test 환경에서 추가 training 을 거친 뒤 사용하는 방안
6. 정리
- conventional 하게 BN layer 를 그냥 사용하고 있었지만, time series 의 경우에는 non-stationary 라면 각 sliding window 가 동일한 분포에서 sampling 되었다고 보고 학습하는 게 합리적이지 않기 때문에, staionary 하게 변경해주는 layer 를 추가해주는 것은 매우 합리적이라고 보임
- 예) (t_1, …, t_10) 와 (t_2, …, t_11), (t_3, …, t_12) 를 동일한 관점에서 봐야하는 data 가 아닌 경우가 훨씬 더 많음 (distribution 이 time 에 대해 invariandt 하지 않은 경우)
- time step 10 개 단위로 성질이 달라지는 data 가 아닌 경우가 많기에
- 다만, BTN layer 혹은 이와 비슷한 layer 를 다른 모델에서 적용한 사례가 별로 없다는 점이 의문
- 꼭 BTN 방식이 아니더라도 어떠한 방식으로든 autoencoder 에 태우기 전에 time series data 를 stationary 하게 변경해서 사용하는 방향으로 가야 할 듯
- 예) (t_1, …, t_10) 와 (t_2, …, t_11), (t_3, …, t_12) 를 동일한 관점에서 봐야하는 data 가 아닌 경우가 훨씬 더 많음 (distribution 이 time 에 대해 invariandt 하지 않은 경우)
- 도메인 관련
- 비록 비공개 data 라서 동일한 data 로 테스트해볼 수는 없지만, 목표로 하고 있는 system domain 의 data 를 사용했다는 점
- DBMS stat metric 중 장애 진단에 중요한 metric 을 DBA 의 domain 지식을 활용해서 feature selection 을 한 후에 해당 feature 만 사용하여 사용했다는 점