Zijian Niu et al., LSTM-Based VAE-GAN for Time Series Anomaly Detection, MDPI sensors, 2020를 간단하게 요약, 리뷰한 글입니다. 개인적인 공부용으로 작성하여 편한 어투로 작성한 점 양해바랍니다.
1. Introduction
- 최근 기술의 발달로 production process 에서 센서가 많아지고 데이터 측정 주기가 짧아지면서 쌓이는 Time Series Data 의 크기가 훨씬 커졌고, anomaly detection 을 통해 장애 분석 및 예측을 하고 전체 생산 효율을 높일 수 있기에 중요성이 더 커졌다.
- Anomaly 정의 ( = outlier )
- 다른 대부분의 관측치와 많이 달라서 무언가 다른 메커니즘으로 발생한 것이라고 의심되는 관측치
- Time Series Anomaly Detection
- statistics based approach ( ARIMA, CUSUM, EWMA ) 등은 실제 산업용 데이터에서 만족할만한 efficiency 와 accuracy 를 보이지 못하였다.
- 최근 몇 년간 DL 기반 unsupervised anomaly detection 방법론들이 제시되었는데, time series data 의 unknown relationship 을 학습하도록 NN 을 짜고, prediction model 을 build 하여 predicted value 와 actual value 가 많이 다르면(residual 이 크면) anomaly 로 판단하는 predictive model 이 대부분이었다.
- LSTM 기반
- Bontemps, L. et al., Collective anomaly detection based on long short-term memory recurrent neural networks
- Hundman, K. et al., Detecting spacecraft anomalies using lstms and nonparametric dynamic thresholding (리뷰 글)
- Chauhan, S. et al., Anomaly detection in ECG time signals via deep long short-term memory networks
- Malhotra, P., et al., Long short term memory networks for anomaly detection in time series
- 기타 MLP 기반, Support Vector Regression 기반 모델들
- LSTM 기반
- 하지만 production process 도메인의 data 가 점점 복잡해짐에 따라서 predict 가 잘 되지 않는 상황이 되어, 이제는 predictive model 들은 적용하기 어렵다.
- 대신 reconstruction-based generative model 은 사용 가능하다고 본다.
- sliding time-window 로 data 를 자른 뒤, reconstruction 하는 AE, VAE 모델이 제안되었고,
- MAD-GAN 과 같이 GAN 기반의 방법론도 제안되었다.
- generator 와 discriminator 에 LSTM 사용
- 하지만, 학습 이후 추론 phase 에는 data 를 real-time space 에서 latent space 로 mapping 한 이후에 사용해야 하므로, 이 mapping Network 의 성능에 의존하게 되는 단점 존재
- 그래서 좋은 mapping 함수를 얻기 위해 vae 를 학습하고, encoder 를 such mapping network 로 사용 !
- decoder 를 gan 의 generator 와 동일시
- 따라서 LSTM-based VAE-GAN 을 제안
- encoder, generator, discriminator 모두 같이 학습
- time dependence 성질을 잡아내기 위해, encoder, generator, discriminator 모두에 LSTM 사용
- model 은 당연히 normal data 만 가지고 학습
- encoder 는 input time series 를 latent space 로 mapping
- generator(= ae 관점에서 decoder) 는 latent vector 로부터 input time series 를 reconstruct
- discriminator 는 받은 time series data 가 input 에서 온건지 generated 된건지 구별
- MAD-GAN 에서는 GAN 따로 학습하고, mapping network 따로 학습하거나 적당한 NN 으로 사용해야 했지만, 본 논문의 방법론은 동일한 train phase 에서 동시에 학습하기 때문에 정확도를 높이면서도 time cost 를 줄일 수 있다.
- 이 방법론은 vision 분야에서 vae 와 gan 을 결합한 방법론이 vae 와 비교했을 때, visual fidelity 와 같은 특정 metric 기준으로는 더 좋은 성능을 내는 것을 보고 영감을 받았다.
- anomaly score는 VAE part 에서의 reconstruction error 와 Discriminator part 에서의 discrimination result 를 함께 사용
2. Materials and Methods
2.1. Time Series
- 사용한 Dataset
- Yahoo
- 학교 인증과정을 거쳐야 제공받을 수 있음 (현재 승인 요청 보낸 상황)
- 총 4개의 data 가 제공되는데, A1Benchmark 데이터만 real data 이고 나머지 data 는 합성된 data 라고 하며, 본 논문에서도 A1Benchmark 데이터만 사용함
- 94866 row 중 1669 anomalies 존재 (1.76 %)
- KPI
- 해당 웹페이지 링크 가입 후 다운받았으나 single variate data 인 것으로 확인되어 관심 x
- Yahoo
- 정규화 방법
- min-max normalization 사용
- train/test split
- train data 는 normal 만 사용했다는 언급 말고는 정확히 어느 구간을 기준으로 train, test data split 했는지는 명시되어있지 않음
- sliding window
- size : 10, step-size : 3
2.2. LSTM-Based VAE-GAN
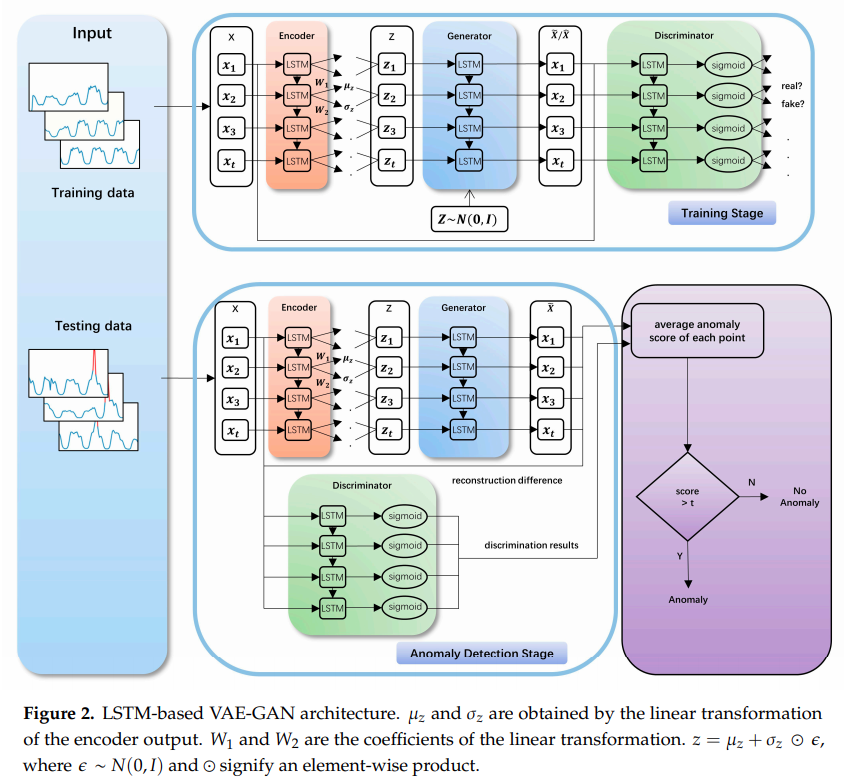
- 일단 model training stage 와 anomaly detection stage 를 구분하겠다.
- training stage 에선 normal time series data 만 받아서, normal data 의 distribution 을 추정하도록 학습된다.
- anomaly detection stage 에선 testing time series data 각각의 average anomaly score 를 구한다.
- 구조
- encoder
- input sample 은 정해진 size 의 sliding window 로 slicing 된 sub-sequence (vector) 를 받음
- 이걸 latent space 로 encoding 하는 역할
- generator
- latent space vector 로부터 input space 의 vector 생성
- discriminator
- input space vector 가 들어오면, 이 vector 가 normal training data 의 분포를 따르는지 판단하고 그 결과를 output 으로 반환
- encoder
- loss function
- notation
x: data samplex~: encoded 된z로부터 generator 를 거쳐 reconstruct 된 vectorx^: N(0, I) 에서 sampling 된z^로부터 generator 를 거쳐 generate 된 vectorDis(.): discriminator 함수(network) 자체 -> output 은 normal data 일 확률- discriminator 는
x~,x^은 0 으로,x는 1 로 구별하도록 학습한다.
- discriminator 는
- loss function 의 자세한 식은 다음과 같으며, 최종 Loss function 은 각 3 개의 Loss function 을 sum 한 것

- notation
- 사용한 hyperparameter
- optimizer : Adam
- learning_rate : 0.001
2.3. Anomaly Score
- anomaly detection stage (inference phase) 에서는 sliding window 처리된 input data 가 들어오면 encoder -> generator 거친 후의 reconstructed sub-sequence 가지고 discriminator 를 통과시켜 input data 가 normal 일 확률을 출력하는 flow 로 이루어진다.
- 이 과정에서 최종적으로 사용할 anomaly score 는 다음과 같은 형태
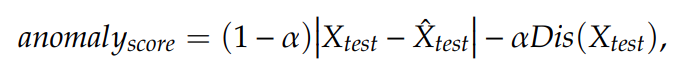
|X_test - X^_test|가 reconstruction error term- ` - Dis(X_test)` 가 discriminator 로부터 나온 abnormal 일 확률 ( (-) 까지 포함한 걸 이 term 으로 보겠음)
- 따라서 abnormal data 라면 두 term 모두 높은 값을 반환
- 저자들이 min-max scale 을 한 이유가 아마도 ` - Dis(X_test)` term 의 범위가 0 ~ 1 사이이므로, recon error 도 그와 비슷한 scale 로 나오도록 균형을 맞추기 위함인 것으로 보임
- sliding window 특성 상 원본 time series data 중 어떤 point 들은 anomaly score 가 여러 번 계산되고, 어떤 point 들은 한 번만 계산되기 때문에, 평균낸 anomaly score 를 최종적으로 anomaly detecting 할 때 사용
- 추가로, anomaly detection 을 위한 optimal threshold 를 결정하기 위해 test set 중 일부를 validation set 으로 사용
- validation set 만으로 threshold 를 결정하려면 validation set 이 test set 을 자~알 대표한다는 가정이 있어야 하는데, 그냥 깔고 가는듯 보임
2.4. Anomaly Detection Algorithm

3. Results
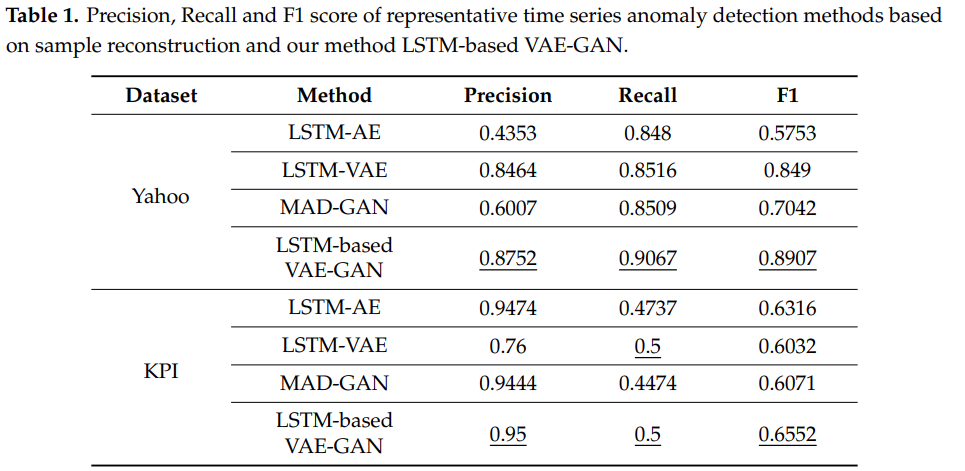
3.1. Comparision with Other Reconstruction Models in F1 Score
- 평가 metric : F1 score
- hyperparameter
- model 구조
- encoder, generator, discriminator : 모두 depth 1, 60 hidden unit 의 LSTM
- latent space dimension : 10
- model 구조
- 성능 비교를 위한 baseline models
- LSTM Autoencoder
- LSTM VAE
- MAD-GAN
- threshold selection
- 정확한 비교를 위해 모두 같은 방식으로 threshold 를 선택
- 구체적인 선택 방법이 논문에 적히진 않았으나, 동일한 validation data 를 기준으로 f1 score 가 가장 높은 threshold 를 선택한 방법으로 추정
- 정확한 비교를 위해 모두 같은 방식으로 threshold 를 선택
- 성능 결과
3.2. Time Spent in the Anomoaly Detection Stage
- inference phase 에 걸리는 시간 비교
- GAN based method 와 비교했을 때는 best mapping network 를 fitting 할 필요 없이 이미 학습해놨기 때문에 당연히 훨씬 빠름 (약 500 배)
- 단, LSTM-AE, LSTM-VAE 와 비교했을 때는, discriminator network 를 추가로 거치기 때문에 당연히 더 느림 (약 2 배)
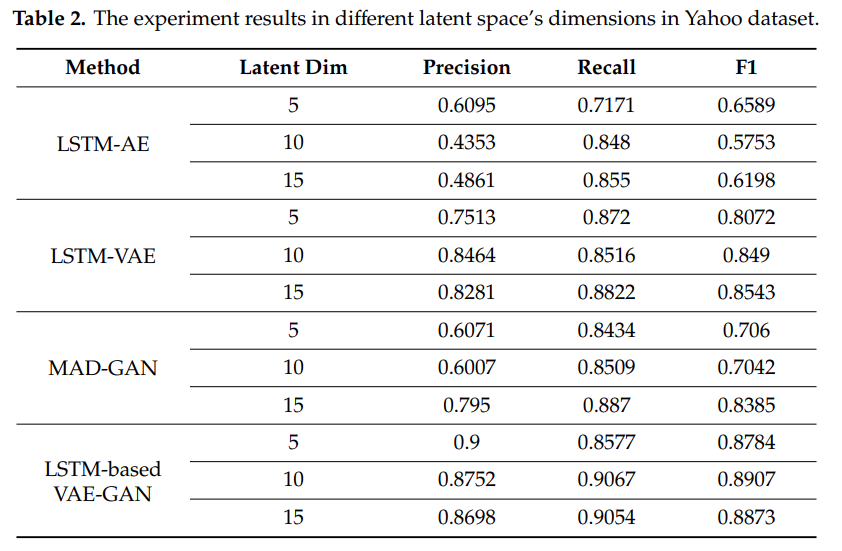
3.3. The Impact of Latent Space’s Dimensions
- latent space dimension 의 정확한 경향성 혹은 특징은 명시된 바 없음
- dataset 에 따라, model 에 따라 최적 latent space dimension 이 다름
3.4. Visual Analysis
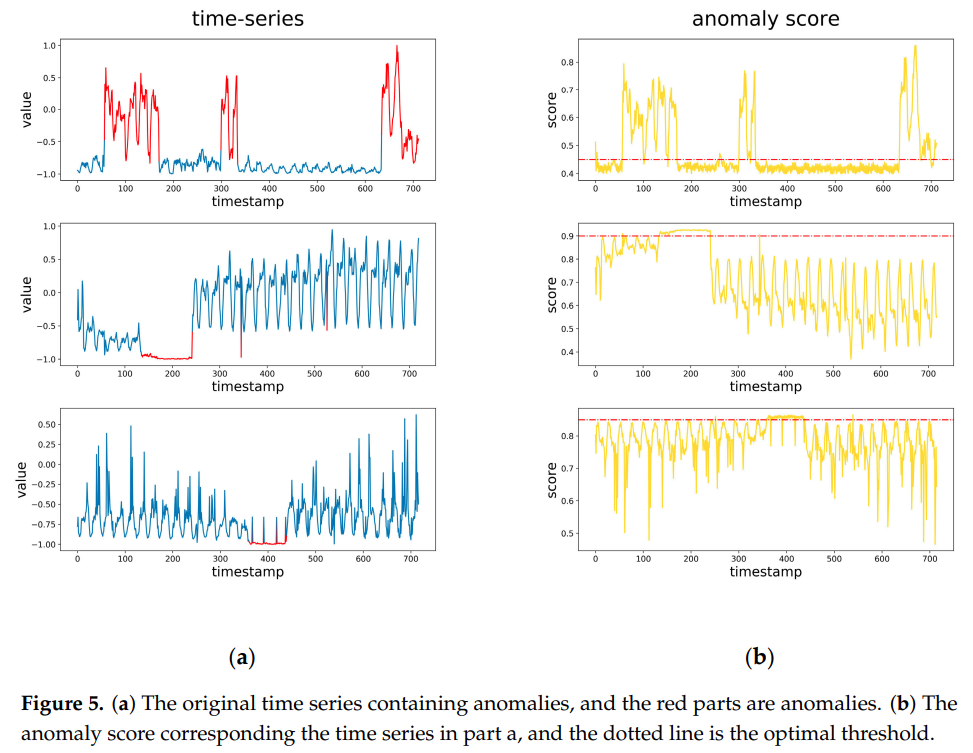
- anomaly score 와 실제 anomaly points 비교해보면 거의 비슷하게 맞춤
4. Discussion
- time series anomaly detection 을 위해 LSTM based VAE-GAN 제안
- training stage 와 anomaly detection stage 구분
- training stage 에서 encoder, generator, discriminator 를 함께 학습해서 encoder 의 중요 정보 mapping 능력과 discriminator 의 검증 능력을 둘 다 취하는 방식
- GAN based method 와 비교했을 때, anomaly detection stage 에서 걸리는 시간을 확 줄여줌
- 몇 가지 limitation 존재
- point anomaly 를 가정하고 이를 detecting 하는 것에 초점을 맞췄다.
- 즉, 연속된 anomaly sequence 가 발생하는 상황에서 이를 detecting 하는 idea 가 들어가진 않았다.
- 이런 형태로 anomaly 가 들어오는 data & task 의 경우에는 이를 반영할 수 있는 model 을 사용해야 한다.
- threshold 를 dynamic 하게 select 하는 것이 효율적이다.
- point anomaly 를 가정하고 이를 detecting 하는 것에 초점을 맞췄다.
5. 정리
- model 구조 자체는 굉장히 합리적이라고 보임, 기존 VAE 보다 확실히 발전된 구조라고 생각 (Discriminator 를 통해 검증하는 term 이 추가적으로 있다는 점)
- 단, 역시 GAN 계열 특성상 학습이 잘 되는지 (잘 수렴하는지)는 직접 테스트해봐야 알 듯
- 최종 anomaly score 를 뽑을 때, reconstruction term 과 discrimination term 의 비중을 어떻게 정할 것인가가 애매하긴 함
- 구현하기에도 어렵지 않은 구조고, RAPP 와 결합을 통해 더 발전된 구조로 구현하기도 쉬워보임
- time dependence 를 반영한 것이 LSTM layer 로 network 를 짰다는 점 말고는 없음
- 하지만 Autoencoder 구조를 기반으로 해서는 이런 historiccal information 을 반영할 수 있는 다른 신박한 방법이 딱히 없어보이기도 함..