Kyle Hundman et al., Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding, KDD, 2018를 간단하게 요약, 리뷰한 글입니다. 개인적인 공부용으로 작성하여 편한 어투로 작성한 점 양해바랍니다.
저자들이 공개한 code 는 다음 링크와 같습니다.
1. Introduction
- Domain
- 우주선에서 측정하는 각종 data : temperature, radiation, power, instrumentation, …
- 잠재적 위험을 미리 감지하는 것이 안전과 돈 모든 측면에서 중요
- 기존 Anomaly Detecting & Alerting 로직
- 사람이 pre-define 한 rule 기반으로 특정 기준에서 벗어나면 anomaly 로 판단
- 하지만 이러한 방식은 전문가의 지식이 매우 많이 필요하며, pre-defined rule 이 계속해서 update 되어야 하는 데 있어서 너무 많은 비용이 소모됨
- 게다가 측정 장비의 발전으로 data 의 양이 커질수록 더 분석하기 힘들어짐
- 하루에 85 Terabytes 의 데이터가 쌓이는 걸 사람이 분석할 수 있겠는가?
- Challenges
- labelled anomalies data 가 부족하기 때문에 unsupervised of semi-supervised 접근 방식이 필요
- heterogeneous & noisy & high-dimensional data
- anomaly detection 이 진단 tool 로써 쓰이려면 반드시 해석력을 제공해주어야 함
- 아무런 인사이트 없이 결과만 제공해준다면 도메인 전문가가 믿고 사용하기 어려움
- false positive 와 false negative 사이의 밸런스
- 본 논문의 의의
- spacecraft data 뿐만 아니라 일반적인 multivariate time series data 에 대해서도 검증을 거침
- high prediction performance 와 intepretibility 를 모두 얻기 위해 LSTM 을 사용한 predictive model 을 제안
- nonparametric, dynamic and unsupervised thresholding 방법론 제안
- various range, behavior 를 갖는 stream data 에 적용할 수 있음
2. Background & Reltated Work
- time series data 에서 anomaly 분류
- point
- single value anomaly
- contextual
- whole data 기준으로는 anomaly 가 아니지만 local neighborhood 기준으로 봤을 때 anomaly 인 single value
- collective
- sequence 단위의 anomaly
- point
- 다양한 domain 에서의 anomaly detection 방법론은 많지만 각각 parameter 결정, 해석력, 확장성, 고성능 리소스 의존 등의 단점이 있음
- out of limit approach
- clustering based approach
- nearest neighbors approach
- dimensionality reduction approach
- 최근 sequence to sequence learning 분야에서 RNN 이 보여준 성능은 압도적이기 때문에 aerospace 분야에서도 RNN 을 도입해보았다.
2.1. Anomaly Detection in Aerospace
- 우주선에서도 위에 명시한 여러 approach 의 구현체를 탑재해서 사용해왔다.
- 하지만 어느 것 하나도 압도적인 방법론이 없었기에 계산량이 적고 직관적이며 이해하기 쉬운 out of limit 방식이 주로 사용되었다.
- 그러나 이제는 data volume 이 감당하기 어려울만큼 커지고 있고 RNN 이 다른 domain 에서 굉장한 성능을 보이고 있으므로 aerospace domain 에서도 적용해보겠다.
2.2. Anomaly Detection using LSTMs
- historical information 을 보존해서 future prediction 에 사용할 수 있는 RNN 계열의 NN 이 NLP 뿐만 아니라 음성 인식, time series forecasting 등 여러 도메인에서 좋은 성능을 내고 있다고 알려져 있음
- multivariate time series data 를 dimension reduction 할 필요 없이 input 으로 사용 가능
- normal data 만으로 학습(fitting)하면 LSTM 은 normal condition 의 system behavior 를 학습
- 일련의 stream data 가 들어왔을 때, model 이 predict 한 값과 비슷하면 정상, 다르면 비정상
- prediction error
- 일련의 stream data 가 들어왔을 때, model 이 predict 한 값과 비슷하면 정상, 다르면 비정상
- LSTM 은 shared parameters across time 을 사용해 time window 의 크기를 specify 할 필요가 없는 방법론이라고 함
- why ?? 어떤 걸 말하는 건지 잘 모르겠음
- lstm 을 사용해서 predict 하는 index 와 실제 그 index 의 label 을 비교하려면 time window 단위로 끊어야 되는 것 아닌가?
3. Methods
3.1. Telemetry Value Prediction with LSTMs
- input 으로 사용하는 data 는 모든 channel 의 관측치를 aggregate 한 multivariate data 를 사용하지만, 예측 모델은 각 channel 마다 따로따로 구성한다.
- 즉, output 이 1 Dimension 인 model 을 각 input feature 의 개수만큼 독립적으로 구축, 학습
- m-dimensional output 을 한꺼번에 predict 하는 model 을 만들면, m 이 클 때 LSTM 의 성능이 떨어지고 놓치는 anomaly pattern이 발생할 수밖에 없음
- 또한 each time step 마다, 바로 다음 time step 만 예측하고 error 를 비교하는 model로 구성
- 이는 processing time 이 적은 model 이 필요한 domain 이기 때문
3.2. Dynamic Error Thresholds
- 1000 여 개의 channel 을 자동으로 모니터링하기 위해서는 predict value 가 anomaly 인지 판단하는 fast, general and unsupervised approach 의 필요성
- 즉, streaming data 의 threshold 를 결정하기 위한 fast & unsupervised approach
- 우선 현 구조에서 prediction error (예측값과 실제값의 차이)가 각 time step 마다 존재하는데, LSTM-based prediction 은 abrupt change 를 잘 예측하지 못하기 때문에 이로 인해 time vs prediction error graph를 그려보면 sharp spike 가 많게 나올 수 있음
- 따라서 이런 에러를 줄이고자 원본 prediction error 에 exponentially-weighted average 를 적용한 smoothed error를 기준으로 다음 unsupervised 방법론을 통해 threshold 를 결정
Threshold Calculation
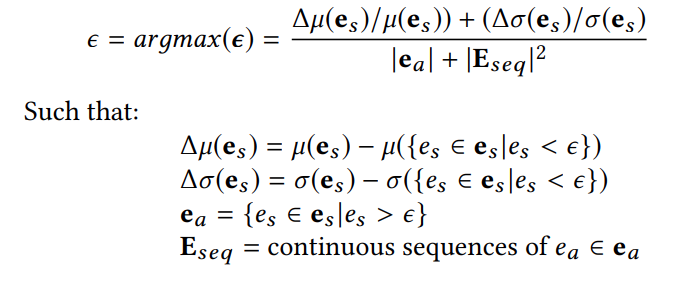
- where
e_s: smoothed error,mu: 평균,sigma: 분산,z: {2, 2.5, 3, 3.5, …, 10} 중 하나의 값- z 는 for loop 로 위 set 의 모든 값을 돌면서 테스트 후, best 성능을 내는 z 로 내부적으로 choice
- 식이 어렵긴 하지만, 코드의 내용을 참고해 간단히 말하면 위 식의 분모를 최소화하면서 분자를 최대화하는 threshold 를 구하는 것
- 분모를 최소화하는 것은 anomaly 의 개수와 연속된 범위를 줄이는 것을 의미하고
- 분자를 최대화하는 것은 anomaly point 를 제외했을 때 mean 과 std 가 얼마나 많이 줄어드는지를 의미
- 그 tradeoff 로 threshold choice
- 이 방법론이 얼마나 합리적인지는 솔직히 잘 모르겠음. 이 방법론을 도입한 충분한 근거를 논문에서는 제시하지 않음
3.3. Mitigating False Positives
Pruning Anomalies
- prediction-based anomaly detection approach 는 threshold 를 선택할 때나, 특정 time 에 대한 anomaly 판단을 내릴 때, 과거 historical data 를 얼마나 참고할 것인지 (
h)에 dependency 가 큼h를 크게 잡으면 computing cost 가 크게 들어 real-time 에는 어울리지 않고h를 작게 잡으면 narrow history 의 information 만 활용하게 되어 false positive 가 많아짐
- memory limit, computing cost 를 줄이면서 false positive 도 줄이는 방법을 제시
- potential anomaly sequence 들이 여러 구간이 있으면 각 구간들의 max anomaly score 를 비교해서, elbow point 를 찾는 것처럼 percent 로 비교했을 때, max score 가 별로 감소되지 않는 구간은 그 구간 전체를 normal 로 reclassifying 해버리는 방법 (아래 그림 참조)
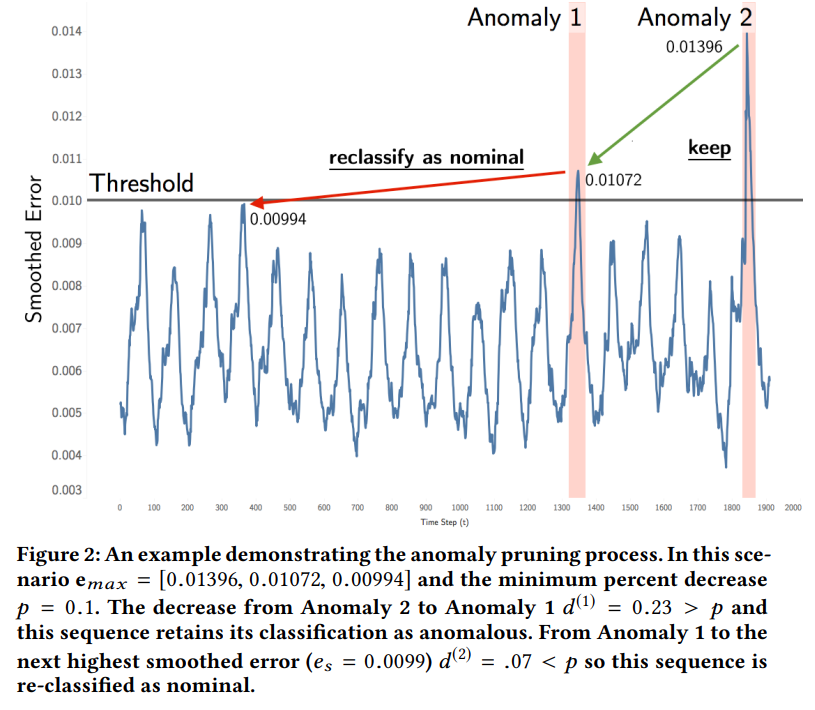
Learning from History
- aerospace 도메인 특성상 비슷한 강도의 anomaly 가 동일 채널에서 반복되지 않는다는 가정을 사용하여 anomaly score 의 minimun 을 정하고, 이를 넘지 않는 anomaly 들은 전부 normal 로 reclassifying 해버리는 방법
- 도메인 전문가의 rule 이나 일부 label 정보가 있다면 이를 바탕으로 anomaly score 의 minimum 또는 maximum 등의 range 를 구하고, 이로부터 pruning 하는 과정을 통해 false positive 를 줄이는 방법은 다른 도메인에도 적용 가능할 듯!
4. Experiments
- 자세한 내용은 생략. 논문 참조
- 사람이 적당한 threshold 를 직접 설정하는 parametric 방법론과 비교했을 때, 저자들이 제시하는 non-parametric with pruning 방법론이 F1 score 가 가장 좋았다.
- 하지만, pruning 방법론도 decreasing percentage
p라는 parameter 를 결정해야 함
- 하지만, pruning 방법론도 decreasing percentage
5. Conclusion
- 최신 LSTM based predicting approach 를 spacecraft 도메인에 적용
- label 정보와 false parametric 가정에 기반하지 않고 threshold 를 dynamically 정하는 방법을 도입
6. 정리
- predictive model 을 사용할 때, output 이 input dimension 과 똑같은 하나의 model 을 학습시키는 게 아니라 각 feature 별로 model 을 따로 두고 학습시키는 게 좋은 경우도 당연히 있긴 할 것으로 생각되지만, high-dimension 일 경우 각각의 feautre 별 model 을 구현해서 학습시키고 사용하는 부분이 내가 직접 적용하기에는 매우 귀찮은 일일 듯
- 위 특징 외에는 일반적인 predictive model 내용과 별다를 것이 없음
- threshold 설정의 문제는 당연히 모든 deep learning model 에서 애매한 부분이므로, 적당한 logic 을 통해 historical context 를 고려한 dynamic thresholding 방법을 시도한 것은 의의가 있음
- 그러나 사실 본문에서 언급한 logic 도 ‘threshold 자체’를 ‘선택’하지 않았을 뿐, ‘threshold 선택 logic’ 을 ‘선택’한 것에 불과하며, 이 logic 을 선택한 완벽한 논리가 있는 것도 아니므로 큰 의미에서의 ‘threshold 선택이 애매하다’는 문제는 계속 안고 가는 논문이라고 생각
- 단, prediction error 에 ewm 등을 통해 smoothing 과정을 거친 error 를 최종 prediction error 로 보는 것은 굉장히 합리적이라고 보임 (LSTM 의 단점을 보완하고, noise 를 줄이기 위한 방법)