Chunkai Zhang et al., VELC: A New Variational AutoEncoder Based Model for Time Series Anomaly Detection, arXiv, 2020를 간단하게 요약, 리뷰한 글입니다. 개인적인 공부용으로 작성하여 편한 어투로 작성한 점 양해바랍니다.
1. Introduction
- Anomaly Detection 이란
- 중요한 정보를 감추고 있는 data 로부터 평소와는 다른 pattern 을 찾아내는 것
- 이 패턴은 random 하게 일어난 것은 아니라고 가정
- 중요한 정보를 감추고 있는 data 로부터 평소와는 다른 pattern 을 찾아내는 것
- Real data 에서의 Anomaly Detecting task
- 실제 data 는 normal 이 훨씬 많은 unbalanced data 이기도 하고, labeling 하는 일은 domain 지식도 필요하며 time cost 도 큰 일이므로 대부분의 anomaly detection 관련 연구는 unsupervised learning 으로 해결하는 방법론 위주
- 과거 연구
- 초반에는 distance, density or angle-based 로 구분하는 method 를 사용했으나, data 의 차원이 높아지고 양이 많아지면 성능이 떨어지며 계산량도 너무 커짐 (그렇다고 차원 축소 후 사용하면 중요한 정보를 잃는다는 문제)
- DL 기반 연구 (For Time Series Data)
- prediction error 기준으로 정상/비정상 판단 (잘 예측하면 정상, 못 예측하면 비정상)
- Malhotra, P., Vig, L., Shroff, G., Agarwal, P.: Long Short Term Memory Networks for Anomaly Detection in Time Series p. 6 (2015)
- Sabokrou, M., Fathy, M., Hoseini, M., Klette, R.: Real-time anomaly detection and localization in crowded scenes. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops. pp. 56–62 (2015)
- Zhou, C., Paffenroth, R.C.: Anomaly detection with robust deep autoencoders. In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp. 665–674. ACM (2017)
- reconstruction error 기준으로 정상/비정상 판단 (잘 복원하면 정상, 못 복원하면 비정상)
- Bayer, J., Osendorfer, C.: Learning stochastic recurrent networks. Eprint Arxiv (2015)
- Slch, M., Bayer, J., Ludersdorfer, M., Smagt, P.V.D.: Variational inference for on-line anomaly detection in high-dimensional time series (2016)
- An, J., Cho, S.: Variational autoencoder based anomaly detection using reconstruction probability. Special Lecture on IE 2(1) (2015)
- Zong, B., Song, Q., Min, M.R., Cheng, W., Lumezanu, C., Cho, D., Chen, H.: Deep autoencoding gaussian mixture model for unsupervised anomaly detection (2018)
- Schlegl, T., Seebck, P., Waldstein, S.M., Schmidt-Erfurth, U., Langs, G.: Unsupervised anomaly detection with generative adversarial networks to guide marker discovery (2017)
- Zenati, H., Romain, M., Foo, C.S., Lecouat, B., Chandrasekhar, V.R.: Adversarially learned anomaly detection (2018)
- prediction error 기준으로 정상/비정상 판단 (잘 예측하면 정상, 못 예측하면 비정상)
- Reconstruction error 를 기준으로 판단하는 Generative Model
- 장점
- 1) training data 자체를 모델링하는 게 아니라, training data 의 distribution 을 모델링하도록 학습하기 때문에, training data 에 속하지 않지만 비슷한 data 들도 생성해낼 수 있음 (strong generalization)
- 2) input space 보다 저차원의 hidden space 에서 normal 과 abnormal data 가 잘 구분될 것으로 예상
- 단점
- strong generalization 이 model 의 출력 자체에는 나쁜 영향이 없지만, reconstruction error 기반으로 anomaly detection 하는 경우에는 normal data 뿐만 아니라 abnormal data 도 reconstruct 를 잘해버리면 문제가 됨
- Gong, D., Liu, L., Le, V., Saha, B., Mansour, M.R., Venkatesh, S., Hengel, A.v.d.: Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. arXiv preprint arXiv:1904.02639 (2019)
- strong generalization 이 model 의 출력 자체에는 나쁜 영향이 없지만, reconstruction error 기반으로 anomaly detection 하는 경우에는 normal data 뿐만 아니라 abnormal data 도 reconstruct 를 잘해버리면 문제가 됨
- 장점
- 본 논문의 주제
- generative model 의 단점을 해결하기 위해 2 가지 구조를 추가한 NN 을 제시 (3.1 절 그림 참고)
- VAE + re-Encoder + Latent Constraint network
- re-Encoder
- RAPP 논문와 동일한 아이디어로 original space 외에 latent space 에서의 reconstruction error 도 anomaly score 에 고려하겠다
- Latent Constraint network
- untrained abnormal sample 도 잘 복원해버릴만큼 train data 를 generalization 하는 걸 막는 layer 를 추가하겠다
- 그럼 이게 잘 작동하려면 그만큼 train data 가 많고 다양한 분포를 가지는 경우여야만 할 듯
- encoder 에서
mu, sigma를 얻어내고N(mu, sigma^2)에서 latent variablez를 sampling 한 후, training sample 과 비슷하게 좀 변형시킨z'를 decoder 에 입력 - constraint network 도 VAE 의 training 단계에서 함께 학습, test 시에는 don’t update
- untrained abnormal sample 도 잘 복원해버릴만큼 train data 를 generalization 하는 걸 막는 layer 를 추가하겠다
- re-Encoder
- VAE + re-Encoder + Latent Constraint network
- time series data 의 특징인 complex temporal correlation 정보를 담을 수 있도록 encoder 와 decoder 에 LSTM 을 사용
- generative model 의 단점을 해결하기 위해 2 가지 구조를 추가한 NN 을 제시 (3.1 절 그림 참고)
2. Reltated Work
- VAE
- main idea
- simple distribution (e.g. Gaussian) with known parameters and superimposable characteristics can theoretically fit any distribution by combining with neural networks
- latent variable 을 sampling 하는 연산은 back propagation 에서 미분할 수 없기 때문에 reparameterization trick 사용
- main idea
- LSTM
- reverse order 도 상관있을 수 있는 data 를 고려해 bidirectional LSTM 사용
3. Proposed Method
3.1. Pipeline of Model
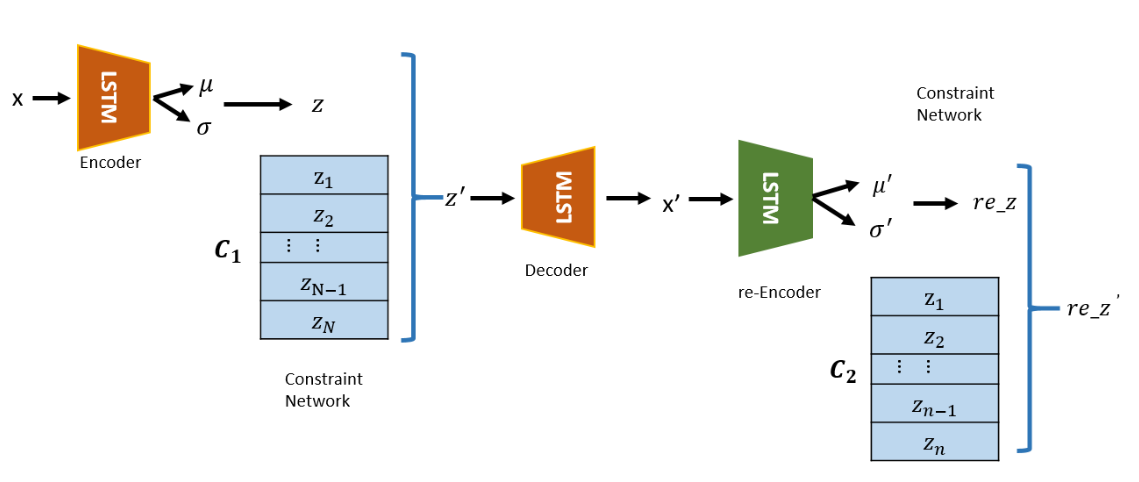
- Re-Encoder
- VAE 로부터 복원된 data 를 다시 encoder 에 태워서 new latent variable
z'을 구하는 구조- RAPP 랑 다른 점은, 이 구조는 loss function 에도 latent vector 간의 L2 distance term 도 추가해서 학습 시에도 고려한다는 점
- input space 에서의 reconstruction error 와 더불어 latent space 에서의 reconstruction error 도 줄이도록 학습
- RAPP 랑 다른 점은, 이 구조는 loss function 에도 latent vector 간의 L2 distance term 도 추가해서 학습 시에도 고려한다는 점
- VAE 로부터 복원된 data 를 다시 encoder 에 태워서 new latent variable
- Contraint Network
- VAE 기반의 generative model 로 anomaly detection 할 때, 안 좋은 성능은 다음 2 가지 경우를 의미할 수 있음
- 1) normal sample 을 잘 복원하지 못함 (normal sample 의 recon error 가 높음)
- 2) abnormal sample 도 잘 복원함 (abnormal sample 의 recon error 가 낮음)
- 하지만, 보통 VAE 의 구조상 train data 자체가 아니라, train data 의 distribution 에서 sampling 한 sample 을 잘 복원하도록 학습하기 때문에 1) 의 경우보다는 2) 의 경우가 잘 생김
- 그냥 주어진 data 가 무엇이든 잘 복원하도록 학습 (loss function 상)
- abnormal data 까지도 잘 복원하는 능력을 제한하기 위한 network
- encoding -> sampling 이후에 적용되는 network 이므로 쉽게 생각해서 decoder 를 조금 더 복잡하게 변경한 것이라고 보면 됨
-
sparse autoencoder 와 MemAE 등의 아이디어와 비슷하게 network 설계

- 간단히 요약하면, 실제 training data 로부터 나온 latent vector 들을 N 차원의 space
{c_1, ..., c_N}의 원소c_i들의 linear combination 으로 이루어진 space 에 projection 해서wC를 얻는데, 계수가 작은w_i는 0으로 간주해서 sparse 하게C에 projection 한z^ = w^ C를 decoder 에 태운다- 즉,
z^는z가 해당 data sample 이 들어오기 전까지 학습한 normal data 의 latent vector 와 비슷하도록(sparse linear combination) 살짝 변경된 vector 가 됨
- 즉,
- encoder 이후의 C_1 과 re-encoder 이후의 C_2 둘 다 학습
- VAE 기반의 generative model 로 anomaly detection 할 때, 안 좋은 성능은 다음 2 가지 경우를 의미할 수 있음
3.2. Loss function
- original VAE 의 loss function 에서 1) re-Encoder 의 KLD term, 2) latent vector 와 re-Encoder 까지 통과한 new latent vector 의 recon error term 이 추가된 형태
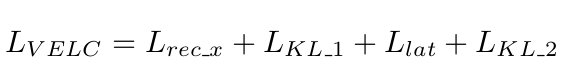
3.3. Anomaly Score
- 원래 recon error 와 latent recon error 의 선형 결합 (weight alpha, beta 는 hyperparameter 로)
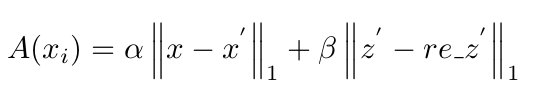
4. Experimental Results
- Dataset
- 4 types of time series data
- sensor, motion, image, network instrusion
- from UCR & UCI public datasets
- but, KDD99 를 제외한 대부분의 data 의 size 가 너무 작은듯
- MNIST 같은 정형화된 dataset 이 왜 없을까?
- 4 types of time series data
- 비교 알고리즘
- AnoGAN, ALAD, MLP-VAAE, Isolation Forest
- 성능 평가 metric
- auc_roc 하나만 사용
- 결과
- 모든 dataset 에서 1 ~ 5 % 이상 성능이 좋음
- anomaly score 의 weight hyperparameter (alpha, beta) 는 결과론적으로는 (0.6, 0.4) 가 가장 좋은 성능을 나타냄
5. 정리
- input data 의 복원을 목표로 학습하는 autoencoder 계열의 NN 에 novelty detection 의 아이디어를 적용하여 anomaly detection task 에 활용하기 위해서는, abnormal data 까지도 훌륭하게 복원하지는 않도록 학습하는 구조를 만들어내야 함
- 이를 가능케 하기 위해서 constrained network 를 추가해서 train data 로부터 얻어진 latent variable 을 최대한 활용하도록 하는 방법이 합리적으로 보이긴 함
- 하지만, 항상 그렇듯이 직관적으로 합리적인 구조보다는 성능이 압도적으로 뛰어난 모델이 대세가 되고, 왜 그 구조가 잘 작동하는지 이유를 끼워맞추는 식으로 해석하는 경우가 많기에 성능이 진짜 좋은지는 돌려봐야 안다
- data 마다 성능이 다르기 때문에, 기준이 될만한 benchmark dataset 이 time-series anomaly detection 분야에 있으면 좋을텐데 여러 논문들을 봐도 각자 서로 다른 dataset 으로, 서로 다른 performance metric 으로 해당 모델이 더 뛰어나다고 주장하고 있으니 어떤 모델이 silver bullet 인지 판단하기 어렵…
- 사실 이건 ML, DL 분야 전체에 걸친 문제인듯
- data 마다 성능이 다르기 때문에, 기준이 될만한 benchmark dataset 이 time-series anomaly detection 분야에 있으면 좋을텐데 여러 논문들을 봐도 각자 서로 다른 dataset 으로, 서로 다른 performance metric 으로 해당 모델이 더 뛰어나다고 주장하고 있으니 어떤 모델이 silver bullet 인지 판단하기 어렵…
- 그동안 reconstruction error 기반의 generative model 을 그냥 anomaly detection 분야에 사용하고 있었는데, 몇 가지 이슈가 있기에 그냥 사용하면 안 된다는 걸 언급하고, 이를 해결할 수 있는 합리적인 구조를 제시함
- Re-Encoder, Constrained network 구조 모두 나름 합리적이라고 보임
- 실제 구현한 code 를 제공하거나 constrained network 에는 어떤 구조를 썼는지를 명시해줬으면 좋았을듯..
- time-series data 의 특성을 반영할 수 있는 아이디어는 encoder, decoder, re-encoder 의 layer 로 bi-LSTM 을 썼다는 것 말고는 딱히 없는듯
- long term info 나 seasonality 등을 반영할 수 있는 구조가 필요