Kieu et al., Outlier Detection for Time Series with Recurrent Autoencoder Ensembles, IJCAI, 2019를 간단하게 요약, 리뷰한 글입니다. 개인적인 공부용으로 작성하여 편한 어투로 작성한 점 양해바랍니다.
1. Introduction
- 사회가 디지털화되어감에 따라 금융, 생명, 교통, 지리 등 많은 도메인에서 시계열 데이터가 생성되고 있으며, 이러한 데이터를 분석하고 이해하고자하는 노력도 커져감
- 본 논문에서는 시계열 데이터가 주어졌을 때, 다른 대부분과 다른 outlier를 검출하는 주제에 집중할 것이며, 특히 label 이 없는 unsupervised 한 상황을 다룸
- 그동안 제시되어온 대부분의 이상 탐지 방법론은 similarity search 또는 density-based clustering 위주였으나, 2015 년쯤부터 autoencoder 계열의 NN 방법론이 제시됨
- autoencoder 계열의 방법론은 input data 를 encoding 하고 encoded 된 hidden representation 으로부터 원본 data 를 복원하는 autoencoder 구조에서, normal data 만으로 학습을 시킨 autoencoder 에 abnormal data 를 통과시키면 복원력이 떨어질 것이라는 아이디어에서 비롯
- hidden representation 이 normal data 의 주요 특징만을 잡아내도록 학습될 것이기 때문
- autoencoder 계열의 방법론은 input data 를 encoding 하고 encoded 된 hidden representation 으로부터 원본 data 를 복원하는 autoencoder 구조에서, normal data 만으로 학습을 시킨 autoencoder 에 abnormal data 를 통과시키면 복원력이 떨어질 것이라는 아이디어에서 비롯
- 이후 single autoencoder 는 train data 에 overfit 될 수 있다는 단점을 보완한 autoencoder ensemble 방법론도 제시됨
- 하지만, autoencoder ensemble 은 non-sequential data 에 초점을 맞춘 구조만 존재했고, 이러한 NN 에 그냥 time series data 를 적용하면 당연히 성능이 떨어짐
- time series outlier detection 를 위해 rnn autoencoder ensemble framework 두 가지를 제시할 예정
- singlel autoencoder 만 학습시키는 게 아니라, 구조가 조금씩 다른 여러 autoencoder 를 모두 학습시킨 뒤, ensemble 해서 사용
- ensemble 할 각각의 autoencoder 는 sparsely-connected rnn 사용
- 학습 시 multiple autoencoder 를 indepenently 학습하면 IF, jointly 학습하면 SF 라고 부름
- reconstruction error 로는 multiple autoencoder 들에서 얻은 recon error 의 median 을 사용
2. Preliminaries
2.1. Time Series
- Time series data :
- time-ordered sequence of vectors
- 정의상으로는 timestamp 간격이 일정할 필요는 없으나, 보통 일정한 시간 간격 단위의 sequence 로 이루어짐
2.2. Outlier Detection in Time Series
- Time Series Dataset
T = <s_1, s_2, ..., s_C>가 주어졌을 때, 특정 outlier score 측정 함수OS에 대하여OS(s_i)가 특정 threshold 보다 큰 경우s_i를 outlier 라고 부름- 즉, 본 논문에서는 point detecting 을 다룸
2.3. Autoencoders
- autoencoder 의 loss function 과 hidden layer 의 차원이 낮다는 network 구조 상, train data 와 비슷한 data 는 reconstruction error 가 낮지만, train data (normal)와 중요한 특징이 다른 data 는 reconstruction error 가 높을 수밖에 없음
- hidden layer 측면에서 train data 와 다른 data 는 outlier 로 보겠다
2.4. Autoencoder Ensembles
- 여러 autoencoder 를 학습해서, outlier detection 의 성능을 더 높이겠다
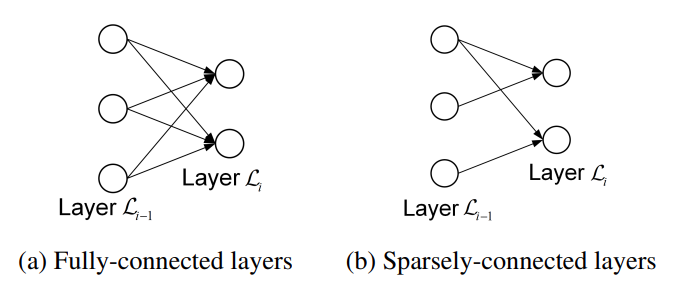
- 단, fully-connected autoencoder 를 여러 개 사용하는 것은 별로 도움이 되지 않음
- network 구조가 완전히 동일하기 때문에 single autoencoder 를 사용하는 것과 별반 다르지 않기 때문
- unit 이 아닌 connection 을 random 하게 remove 한 sparsely-connected autoencoder 를 여러 개 학습시킨 뒤, ensemble !
- dropout 과 다른 점은 dropout 은 epoch 마다 drop 되는 connection 이 random 하게 선택되지만, sparsely-connected 는 전체 training 과정의 맨 앞에서 random 하게 drop 한 뒤, 학습 중에는 고정됨
- 하지만, Chen et al., 2017에서 제시된 autoencoder ensemble 구조는 sequential data 를 사용하기에는 적합하지 않음
- 따라서 sequential data 에 사용할 수 있는 autoencoder ensemble framework 를 제시하겠음
3. Autoencoder Ensembles For Time Series
3.1. Sparsely-connected RNNs (S-RNNs)
- seq2seq model 자체로도 time series outlier detection 을 위한 autoencoder 로 쓸 수 있음
- decoder 에서는 reverse order time series 로 복원
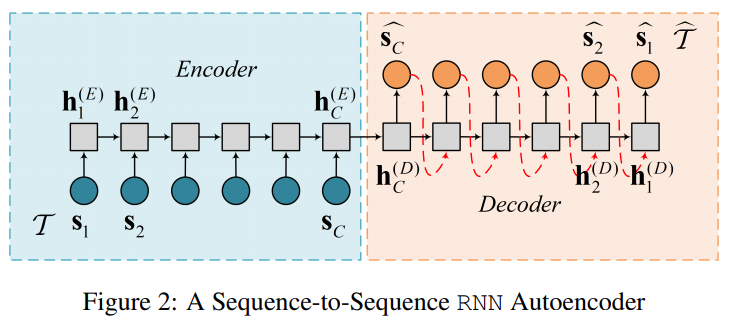
- 하지만, 이 구조에서는 autoencoder ensemble 을 쓸 수가 없는 게 RNN unit 들을 연결하는 connection 하나를 제거해버리면 아예 train 을 진행할 수 없는 문제가 있음
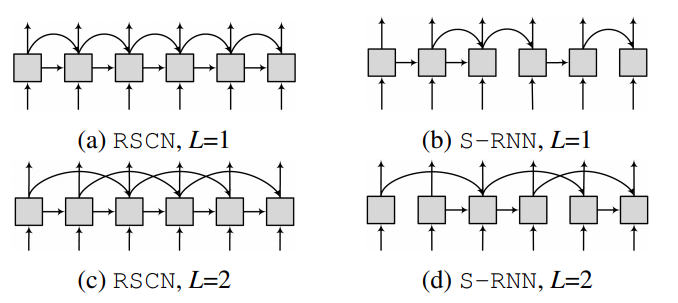
- 따라서 Recurrent Skip Connection Networks (RSCNs) 로 RNN unit 간의 추가적인 연결을 한 구조를 사용하자
-
각 RNN unit 이 직전 hidden state (
h_t-1) 로만 연결된 게 아니라, L 번째 과거 hidden state (h_t-L) 와도 연결됨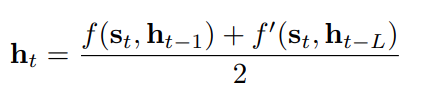
-
이러한 RSCN 에서 기존 rnn unit 간 original connection 또는 skip connection 중 최대 1 connection 만 drop 한 sparsely connected rnn 구조로 변환하면 다음과 같이 되어서, train 을 진행할 수 있음
- e.g.)
w_t := (w^f_t, w^f'_t) in {(0,1), (1,0), (1,1)}
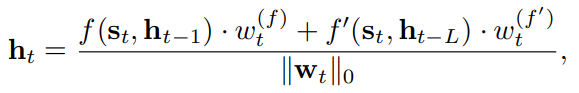
- rnn unit 간 connection 최대 2 개인데, random 하게 drop 하되, drop 하지 않거나 하나만 drop 하는 구조
- e.g.)
-
3.2. S-RNN Autoencoder Ensembles
- ensemble 을 위해 위의 Skip Connection 을 더한 S-RNN autoencoder 를 여러 개 만들어 학습
- 단, 여기서 multiple autoencoder 를 integrate 하는 방식에 따라 2 가지 다른 framework 제시
3.2.1. Independent Framework
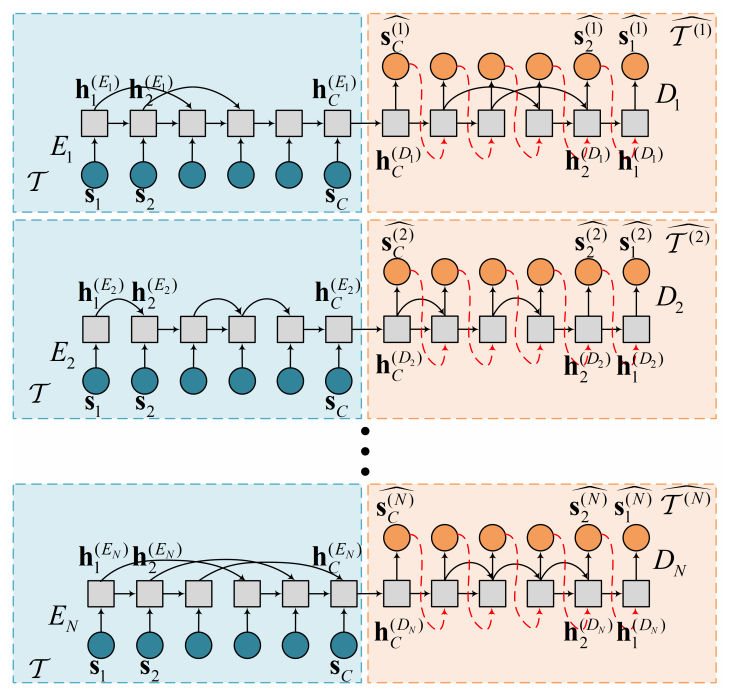
- N 개의 S-RNN autoencoder 가 있으며, 각각은 완전히 independent 하게 각각의 loss function 을 최소화하는 방향으로 학습
- sparseness weight vector
w_t도 각 autoencoder 마다 다르게 정의
3.2.2. Shared Framework
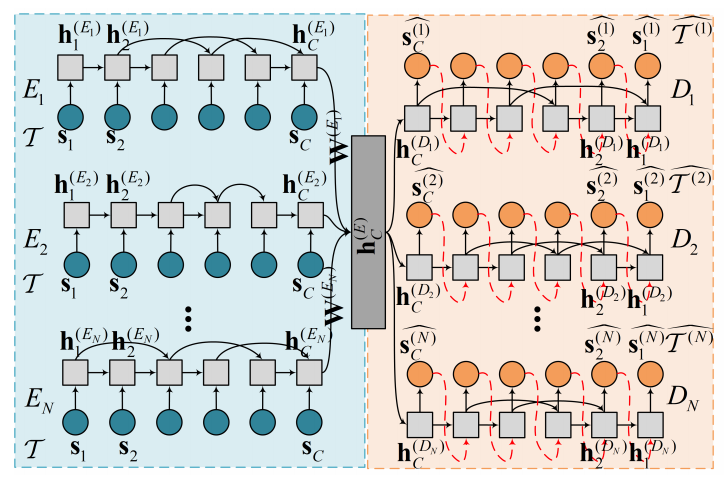
- Multi-task learning 과 비슷하게 각 encoder 의 output vector 를 linear combination (weight 은 trainable parameter)한 shared layer 를 하나 두고, 적당히 결합한 loss function 을 최소화하도록 jointly train
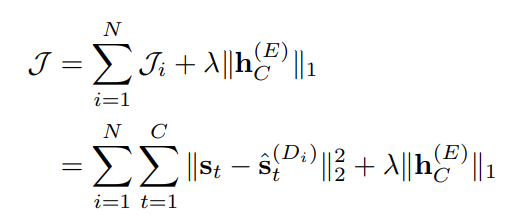
- L1 regularization term 은 shared hidden state 를 sparse 하게 만들어서 특정 encoder 가 overfit 하는 걸 막아줌
3.3. Ensemble Outlier Scoring
- IF, SF 모두 outlier scoring 은 각 autoencoder 의 outlier score 의 median 으로 설정
- mean 대신 median 을 사용한 이유는 overfit 된 autoencoder 의 영향을 줄이기 위함
4. Experiments
4.1. Experimental Setup
- Datasets
- timestamp 기준으로 exclusive 하게 sliding window 를 잘라서 input 으로 사용
- Existing Solutions
- IF, SF 와의 성능 비교를 위해 lof 부터 lstm autoencoder 까지 8 개의 model 도 돌림
- Hyperparameter Setting
- IF, SF 에서 RNN unit 대신 LSTN unit 사용
- activation function 으로 tanh 사용
- LSTM unit = 8
- autoencoder 개수 = 40
- jump step size L 과 sparse weight vector w_t 는 random
- 성능 평가 metric
- threshold 정한 뒤에 평가하는 것은 non-trivial 하므로, threshold choice 에 independent 한 PR-AUC 와 ROC-AUC 로 평가
4.2. Experimental Results
4.2.1. Accuracy
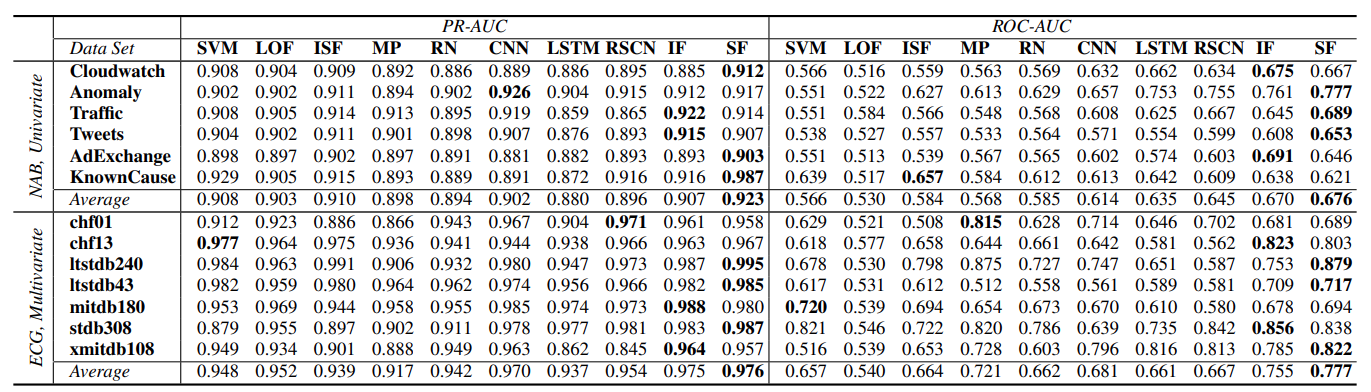
- pr-auc 는 ML 이나 DL 이나 큰 차이 없지만, roc-auc 는 DL 이 훨씬 나음
- 이는 FPR 이 낮고 TNR 이 높다는 걸 의미하며, outlier detection 은 보수적으로 detecting 해야 하는 도메인이 많은 점에서 활용도가 높음
- SF, IF 가 RandNet (non-sequential data - autoencoder ensemble) 보다 성능 좋음
- time series data 용으로는 SF, IF 가 더 적합하다는 걸 의미
4.2.2. Effect of N (multiple autoencoder 개수)
- 저자들이 N 을 10, 20, 30, 40 으로 테스트해봤을 땐, N 을 높일수록 성능이 좋았음
- 하지만, 계속 우상향할지는 의문
4.2.3. IF vs SF
- evaluation metric 으로 비교하면 SF 가 더 좋음
- 이로부터, shared multi-task learning 이 효과적일 것이라고 추측은 가능
- 하지만, 이론적 근거는 없음
- SF 의 단점은 computing resource 가 더 필요하다는 점
- 약 40 개의 LSTM layer 포함한 autoencoder 를 함께 학습하므로 고성능의 memory, cpu, gpu 가 필요
4.2.4. Effect of L
- 1, 2, 5, 10, 20 을 시도해보았는데, 1 ~ 10 까지는 유의미한 성능 변화가 없는 걸 봐서는 temporal information 의 차이는 거의 없음
- 하지만, 20 에서는 정확도가 유의미하게 decrease 하는 걸 봐서는 short term information 이 중요하긴 함
- 이는 data 마다 step 이 다를 것으로 봄
- 특히, seasonality 를 가진 data 의 경우
5. Conclusion
- Future work
- denoising autoencoder, vae 와 같은 다른 autoencoder 에 적용
- embedding, attention 구조 적용
6. 정리
- 우선 resource 제한 상 IF 방식으로 구현해볼만 할 듯
- sliding window 크기를 너무 크게하면 seq2seq 구조 autoencoder 의 특성상 decoder 에 넘겨줄 hidden state, cell state 에 충분한 정보를 담지 못하게 되어버릴 가능성이 높음
- 여기선 seq2seq 와 달리 train 과정에서도 teacher-forcing 을 사용하지 않고, 그냥 decoder 의 각 unit 의 출력을 다음 unit 의 입력으로 넣어주는 auto-regressive 한 구조
- seq2seq 를 NLG 에서 사용할 때와 다르게, input 을 그대로 복원하는 task 에서 진짜 input 을 넣어주면 너무 쉬운 task 라 hidden state 의 정보가 거의 필요없어지고, 그럼 hidden layer 가 유의미한 특징을 잡아내지 못하는 방향으로 학습됨
- attention 을 어떻게 끼얹을 지?