이번 글은 UC Berkelely 에서 2018년 3월, 2019년 3월, 2019년 11월에 부트캠프 식으로 진행된 Full Stack Deep Learning 강의의 Week 2 내용을 정리한 글입니다.
2019년의 강의 영상 및 자료가 free online material 로 공개되어있어 해당 자료를 바탕으로 공부하고 요약, 정리한 내용입니다. 대상 독자를 정해두고 작성한 글이라기보다는 미래의 저를 위해 작성한 요약 형태의 글에 가까우므로, 보다 자세한 내용은 해당 강의를 직접 확인하시면 좋을 것 같습니다 : 링크
Week 2 : Infrastructure and Tooling
1) Overview
- 이상 vs 현실
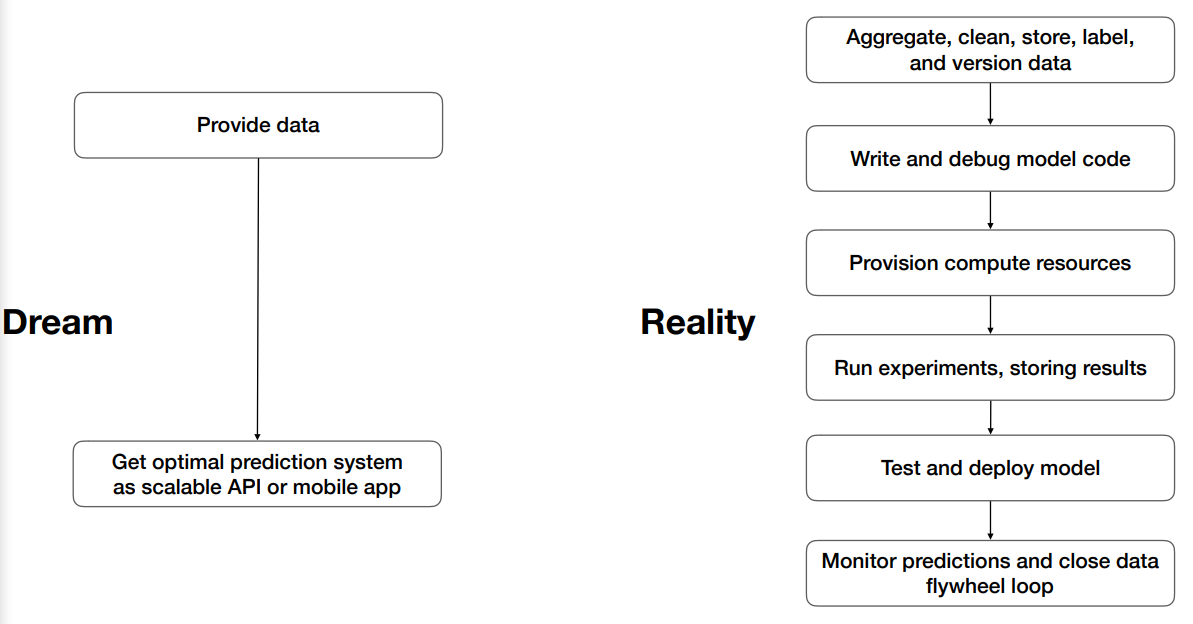 (Data 에서 의미있는 서비스를 만들기까지의 과정)
(Data 에서 의미있는 서비스를 만들기까지의 과정)
- Deep Learning Service 를 만드는데 필요한 Infrastructure & Tools
2) Software Engineering
“모델링 및 서비스 개발 시 필요한 것들”
- Language : Python 이 대세
- scientific, data computing 을 위한 library 가 많음
- IDE :
- Jupyter Notebook
- 다음과 같은 단점이 있으니 지양하자
- versioning
- IDE is primitive
- hard to test
- execution 순서에 의존
- hard to run long or distributed tasks
- 즉, 처음 EDA 시에 draft 용으로는 좋지만 production 용으로는 안 좋음
- (개인적으로는 Deploy 의 어려움 때문에 서비스 개발 시에는 적합하지 않는다고 생각하지만, 로컬에서 여러가지 데이터 분석을 시도해보는데는 좋다고 생각)
- 다음과 같은 단점이 있으니 지양하자
- 대신 vscode, Pycharm 등의 IDE 를 사용해서 Linter, Type Hint 등을 활용하자
- Jupyter Notebook
- Streamlit
- 주로 사용하는 로직들이 템플릿화되어있어서, python code 상에서 decorator 만을 사용해서 interactive 한 web app 을 간단하게 만들기 좋음
3) Computing and GPUs
“어떤 인프라를 사용해야 하는가”
- 단계별로 필요한 인프라 수준이 다름
- Development 단계
- quick compile & 쉬운 debugging 조건
- GUI 가 지원되어야 좋음
- ⇒ 1 ~ 4 GPU 수준이면 충분
- Training / Evaluation 단계
- Hyperparameter Optimization
- Large model 을 학습할 수 있을만큼의 스펙이 갖춰져야 좋 음
- private or cloud cluster of many GPU instances
- Development 단계
- 좋은 성능을 내는 모델을 학습하기 위해선 large model 로 만들어야 하는게 점점 트렌드가 되어가고 있음
- (물론 creativity 도 중요함 !)
- On-prem 구축 vs Cloud Provider 사용
- 회사의 여러 상황에 따라 취사 선택
- fee 관련 내용은 생략
4) Resource Management
“ML Team 에서 관리해야 하는 자원과 툴”
- What Resources?
- 여러 사람들
- 여러 서버
- 여러 환경
- Solutions ?
- people & issue manangement tool
- 스프레드시트
- Slack, Jira, …
- IaC 를 위한 tool
- bash, slurm
- 패키징, 배포 tool
- docker, k8s
- kubeflow
- people & issue manangement tool
5) Frameworks and Distributed Training
“DL 개발 편의와 병렬 처리를 위한 툴”
- DL Framework
- 특별한 이유가 있는게 아니면 웬만하면 Tensorflow or PyTorch 쓰자
- research & production 둘 다 좋음
- research 쪽에선 pytorch 선호
- job post 쪽에선 tensorflow 선호
- 특별한 이유가 있는게 아니면 웬만하면 Tensorflow or PyTorch 쓰자
- 분산 학습은 크게 두 가지 갈래
- data 병렬 처리
- data 를 batch 단위 등으로 partitioning 해서 multi-gpu 혹은 multi-node 에서 parallel 하게 사용
- 거의 linear 한 정도의 속도 향상
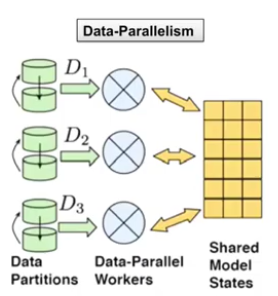 (Data 병렬 처리)
(Data 병렬 처리)- model 병렬 처리
- 연산을 병렬 처리
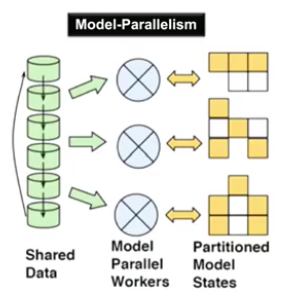 (Model 병렬 처리)
(Model 병렬 처리) - data 병렬 처리
- 참고할만한 open source distributed computing framework on python
- Ray
- RaySGD
- Horovod
6) Experiment Management
“모델링 작업 시 관리 툴”
- 실제로 개발하다보면 여러 모델을 계속 테스트해보기 때문에, 나중에 보면 어느 모델이 어떤 파라미터를 사용하고 어떤 데이터로 학습한 모델인지 헷갈리는 경우가 발생함
- 이를 막기 위해서는 다음과 같은 툴로 관리
- Tensorboard
- 로컬에서 작업하며 하나의 모델을 보기에는 좋지만, 여러 모델을 관리하고 예전 모델을 저장하고 이런 작업에는 부적합
- Losswise
- git commit 으로 tracking 가능 & 여러 모델의 exp 결과 summary 가능
- comet.ml
- losswise 와 동일 기능 제공
- Weights & Biases
- losswise 와 동일 기능 제공
- MLFlow
- losswise 와 동일 기능 제공
- Tensorboard
7) Hyperparameter tuning
“HPO 자동화 툴”
- 최적의 hyperparameter 조합을 찾는 건 너무 어려우니 시간과 자원의 절약을 위해 다른 tool 을 사용해 HPO 를 합시다
- Hyperopt
- python lib
- Random Search 또는 TPE 알고리즘으로 HPO 수행
- Ray Tune
- python lib
- PBT, BayesOptSearch, HyperBand 알고리즘으로 HPO 수행
- Sigopt
- HPO 를 API Service, Platform 으로 제공하는 회사
- Hyperopt
8) All-in-one Solutions
“모든 작업을 하나의 프로그램으로 수행하고 싶다면..”
- 2 장에서 다룬 모든 작업들이 모듈이 분리가 되어있어 사용하기 어렵다면, 다 제공하는 All-in-one solution 을 사용해도 좋음
- FBLearner Flow
- Michelangelo
- Uber
- TensorFlow Extended (TFX)
- Google Cloud AI Platform
- Amazon SageMaker
- AWS
- Neptune, FloydHub, Paperspace, Determined AI, Domino Data Lab 등
- FBLearner Flow
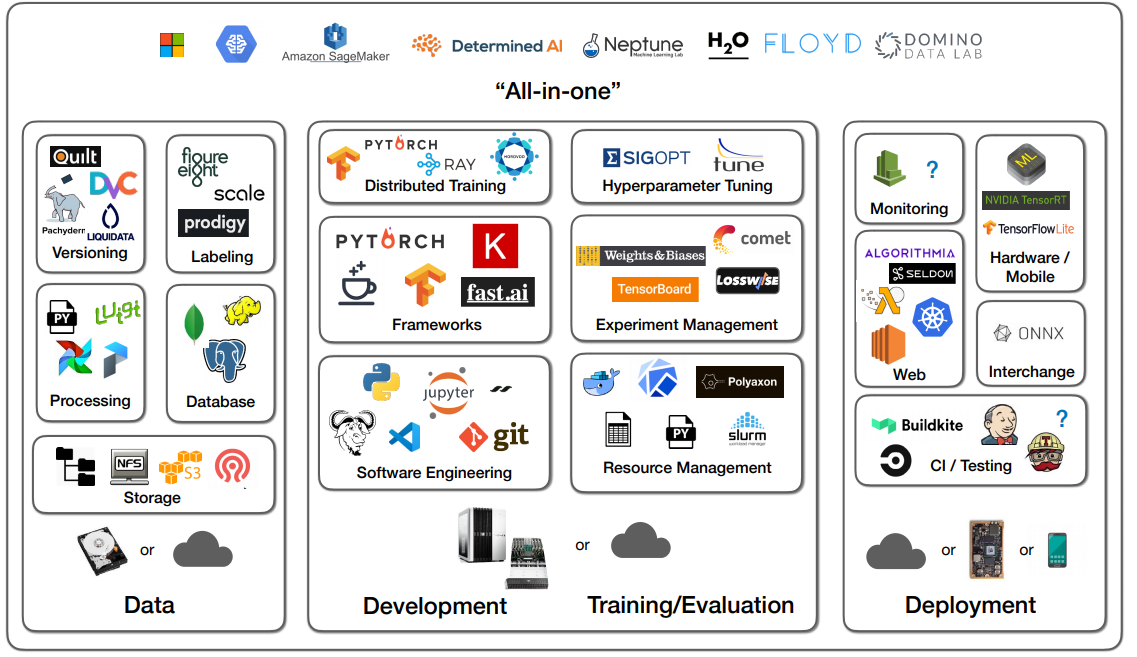
- 위의 제품 요약 비교
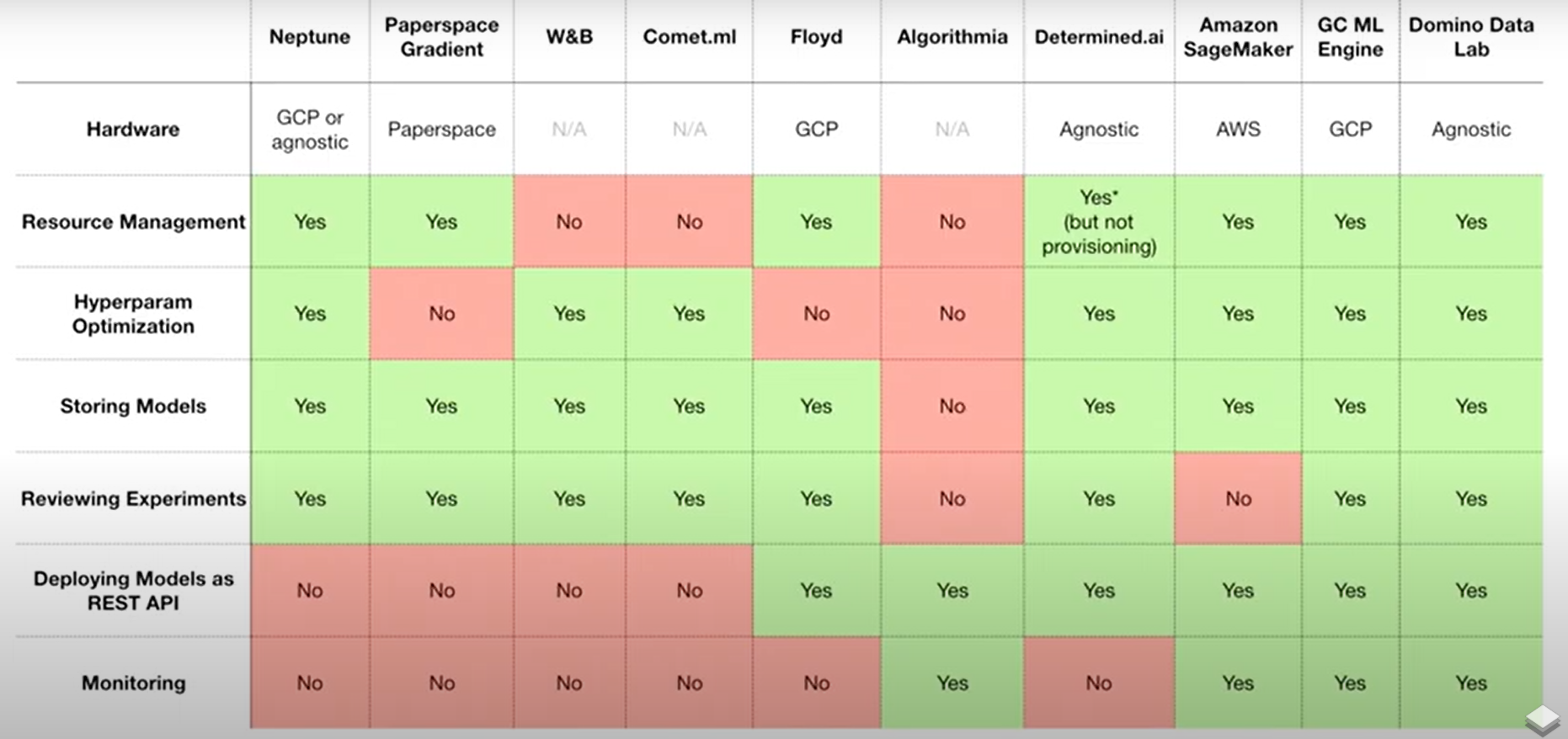 (각 제품별 비교)
(각 제품별 비교)- (강의자는 Domino Data Lab 추천)