이번 글은 UC Berkelely 에서 2018년 3월, 2019년 3월, 2019년 11월에 부트캠프 식으로 진행된 Full Stack Deep Learning 강의의 Week 1 내용을 정리한 글입니다.
2019년의 강의 영상 및 자료가 free online material 로 공개되어있어 해당 자료를 바탕으로 공부하고 요약, 정리한 내용입니다. 대상 독자를 정해두고 작성한 글이라기보다는 미래의 저를 위해 작성한 요약 형태의 글에 가까우므로, 보다 자세한 내용은 해당 강의를 직접 확인하시면 좋을 것 같습니다 : 링크
TMI 로 2020년부터는 해당 대학에서 정식 강의로 진행되고 있다고 하며, 2021년 Spring 학기부터는 온라인 강의로 진행되어 매주 월요일마다 업로드한다고 합니다. syllabus 를 확인해보니 21년 강의는 과거 강의와는 조금 다른 형태인 것 같고, 아직까지는 첫 주차 강의만 업로드되어있어 저는 2019년 자료를 따라갈 예정입니다.
개요
- Deep Learning 은 많은 분야에서 잠재력을 가지고 있고, Deep Learning 의 여러 모델에 대한 개념을 설명하는 등 이론적인 부분을 다루는 좋은 강의는 많음
- 하지만, DL model 을 구성하고 학습시키는 것은 현업에서의 ML/DL 프로젝트의 전체 과정에서는 극히 일부분에 불과함
 (‘그’ 그림)
(‘그’ 그림)
- Production level 에서의 DL 프로젝트를 진행하기 위해서는 여러 작업들이 필요하며, 다음과 같이 분류를 해서 하나씩 다뤄볼 예정임
- Problem 을 정의하고 수학적으로 표현 & Project 에 드는 공수 예상
- Data 를 찾고, 전처리하고, 라벨링하고, 증축하는 과정
- Problem 에 알맞은 framework 를 선택하고, 학습과 배포를 위한 Infra 를 구축
- 모델 학습 과정에서의 Troubleshooting 과 모델의 배포를 위한 Reproducibility 검증
- 확장성을 고려한 model 배포
- 강의에서 말하는 대상 수강생
- DL 의 기본적인 개념 이해
- python 기본적인 프로그래밍 가능
- vcs, unix 환경 그리고 software 개발 프로세스에 대한 이해
Week 1 : Setting up ML Projects
1) Overview
- DL 을 과학이라 할 수 있는가?
- 매우 다양한 논쟁을 불러일으키는 주제
- 이번 강의의 목적은 이런 얘기는 제쳐두고, 어떻게 하면 DL 을 현업에서 그리고 Engineering 단계에서 더 잘 적용할 것인가에 집중
- 현업에서는..
- 소위 말하는 Big company 에서도 85 %의 AI Project 가 실패
- 왜 실패하는 걸까?
- 1) AI 분야는 still research 인 분야이기 때문에 100 % 의 정확도를 기대해서는 안 된다는 걸 간과
- 2) 아직 기술의 발전이 상용화될 정도는 아닌 분야가 많음
- 3) Research level 과 Production level 의 간극을 좁히기 어려움
- 4) 성공/실패의 기준을 명확히 정하기 어려워 진행 상황을 파악하기도 어려움
- 5) ML Team 매니징 능력을 갖춘 인력 부족
- 이번 주에 다룰 내용
- Lifecycle
- production ML system 을 만드는 과정에서 어떤 일들이 일어나는지
- Prioritizing
- project 의 실현 가능성과 비즈니스 임팩트 평가
- Archetypes
- ML project 매니징 방법
- Metrics
- ML project 가 잘 진행되고 있는지 평가 기준
- Baselines
- ML model 의 성능이 어느 정도인지 평가 기준
- Lifecycle
2) Lifecycle
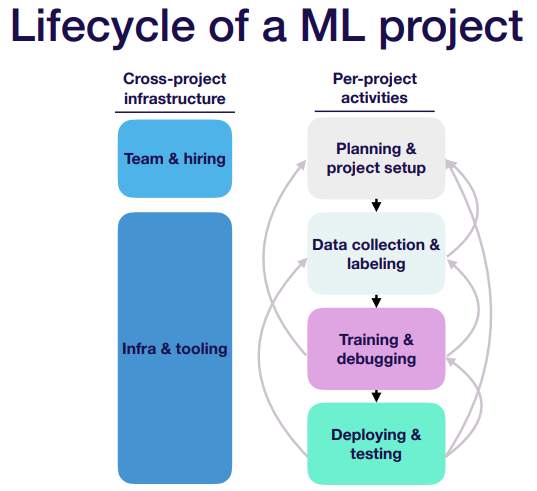 (끝날 때까지 끝난 게 아니다)
(끝날 때까지 끝난 게 아니다)
“가장 중요한 건 각 step 을 진행하는 과정이 one-way flow 가 아니라는 것”
- 이전 step 으로 돌아가야 하는 때 (when, why, where)를 알고 있어야 함
- training 중 data 에 문제가 있다고 판단되면 data collection step 으로 가고,
- 평가 metric 설정이 잘못되었다고 판단되면 planning step 으로 가고,
- testing 단계에서 실현 불가능한 task 라고 판단되면 planning step 으로 다시 가고,
- …
3) Prioritizing
“어떤 프로젝트에 우선순위를 두고 진행해야 하는가”
- High Impact
- prediction cost 는 작고, business 가치는 큰 문제
- 상당 부분 자동화 가능한 문제
- High Feasibility
- dataset 을 구할 수 있는가, 구하기 쉬운가, 라벨링 과정이 필요한가, 라벨링 cost 가 작은가
- 어느 정도의 정확도를 요구하는 문제인가
- 너무 무리한 accuracy 를 요구하는 task 는 아닌가
- 잘못 prediction 하면 critical 한 task 는 아닌가
- ML/DL 로 풀 수 있는 문제인가
- 참고할 수 있는 최소한의 published research/work 가 있는가
- computing cost 가 너무 크진 않은가
- 가진 자원으로 해결할 수 있는 문제인가
- 풀기 어려운 문제 예시
- 출력이 복잡한 경우
- 3d reconstruction, video prediction, dialog
- 높은 수준의 정확도, 신뢰도를 요구하는 경우
- high-precision estimation
- out of distribution 판단
- 높은 수준의 일반화가 요구되는 경우
- self-driving
- small data case
- 출력이 복잡한 경우
4) Archetypes
“ML project 를 대분류하자면 어떻게 되느냐?”
- 1) 이미 있는 project 를 개선하는 project
- ex) IDE 의 code completion, video game AI
- key point)
- 실제로 성능 개선을 하는게 확실한가?
- 비즈니스 임팩트가 있는가?
- Data flywheel 을 만들어낼 수 있는가?
- more user → more data → better model → more user → … cycle 반복
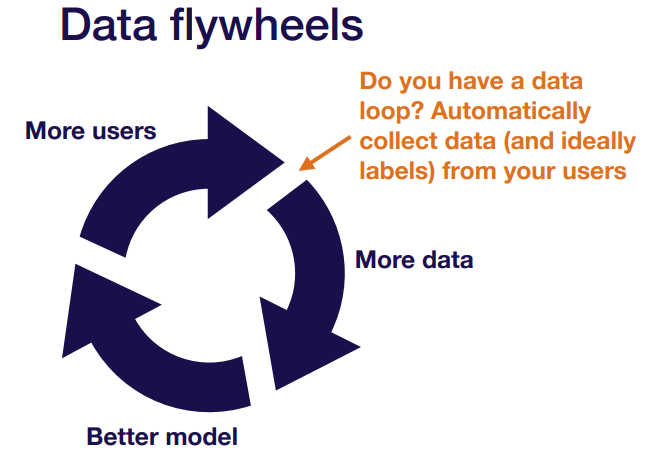 (선순환의 좋은 예)
(선순환의 좋은 예)
- 2) 수작업을 도와주는 project
- ex) IDE 자동완성, email 자동완성, UI sketch 를 code 로 변환
- key point)
- 얼마나 유용한가?
- 모델 학습에 활용할 data 구하기 쉬운가?
- 3) 수작업을 자동화하는 project
- ex) full self driving, automate coding
- key point)
- validation dataset 이 아니라 실제 환경에 배포되어 test dataset 으로 운영할 때, 어느정도의 성능을 원하는가?
- data labeling 작업이 얼마나 덜 비싼가?
5) Metrics
“Problem 과 요구사항을 가장 잘 설명할 수 있는 metric 을 하나 정하고, 이 metric 을 optimize 하는 방향으로 학습해야 함”
- 물론 ! 진행하면서 이 metric 은 변경될 가능성이 높긴 함
- 여러 metric 후보들을 적절히 결합하거나
- threshold metric 으로 사용하거나
- ex) 속도는 이 정도 threshold 만 만족하면 되는데, f1 score 는 높으면 높을 수록 좋음
- domain 지식이 결합된 새로운 KPI 를 만들어서 사용하거나
- Real world 에서는 metric 을 결정하기가 어려운 경우가 많음
6) Baselines
“모델 평가 기준점을 무엇으로 잡을 것인가?”
- 모델 성능 평가의 기준치
- SOTA model
- Human level performance
- Rule-based model 과의 비교
- Human baseline 을 만드는 방법
