해당 글은 towards data science 에 기고된 포스트 How music can be turned into data set을 번역한 글이며, 원글 작성자 Farsim Hossain 의 허락을 받고 포스팅함을 밝힙니다.
좋은 내용이라 개인 공부할 겸 번역을 진행하였습니다만, 의역이 다소 포함되어 있으며 저의 개인적인 코멘트도 ‘이탤릭체 + 회색 글씨’로 포함되어 있습니다.
음악을 데이터로 표현하는 방법
데이터 사이언티스트의 시각에서 음악에 대해 살펴보기
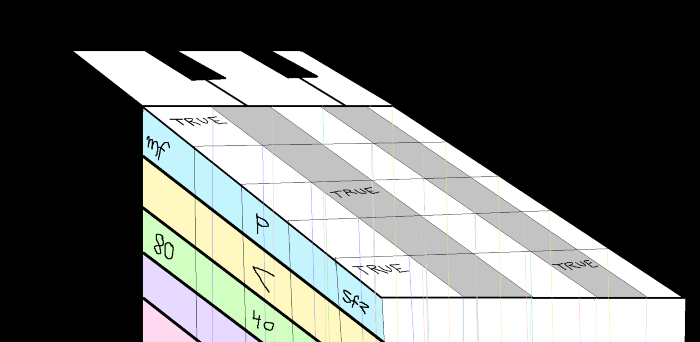
‘반짝 반짝 작은 별’을 데이터셋으로 표현하면 어떤 모습일까요?
Spotify’s와 같은 음악 관련 데이터셋은 이전부터 존재했습니다. 이러한 데이터셋에서 각각의 행은 하나의 노래를 나타내며, 에너지, 어쿠스틱성, 댄스성 등 노래에 대한 중요한 정보를 feature 로 가지고 있습니다. 이런 변수들로 노래의 특징을 표현할 수도 있지만, 노래 전체를 데이터의 구성으로 표현할 수도 있습니다.
- 인간이 분류한 카테고리로 노래의 특징을 분류해서 노래를 정의하는 게 아니라, 노래 그 자체를 음정, 박자, 화성, 세기 등의 column 을 포함한 (time series) sequence data 로 표현할 수 있다는 의미다.
악곡(musical piece)의 기본 요소
악곡을 데이터셋으로 표현하는 방법을 이해하기 위해서는 먼저 음악 이론에 대한 몇 가지 기본적인 내용을 알아야 합니다. 관련 용어에 익숙하지 않은 사람들을 위해 최대한 간략하게 설명하겠습니다.
Note(음)는 음입니다. 음악에는 12 개의 음이 존재합니다: C, C#, D, D#, E, F, F#, G, G#, A, A#, B. B 이후에는 C 부터 새로운 옥타브가 시작됩니다. 음들은 특정 Tempo(템포)로 연주됩니다. 템포는 악곡을 얼마나 빠르게 혹은 느리게 진행할 건지를 결정합니다. Time Signature(박자 기호)는 특정 악곡에서 각각의 Bar(마디)에 몇 개의 비트가 들어갈 것인지를 결정합니다. 마디는 시간의 한 구간을 말합니다. 예를 들어, 박자 기호가 4/4 라는 말은 한 마디 안에 4 개의 비트가 있고, 음악의 cycle(주기)를 완성하는 데 4 개의 마디가 필요하다는 것을 의미합니다. 두 개 이상의 음을 함께 연주하는 경우, 예를 들어 C, E, G 를 함께 연주하는 경우 chord(화음 또는 코드)을 이루었다고 말합니다.
표현 방식 또한 음악의 중요한 요소입니다. 사람이 피아노, 기타 등의 악기를 연주할 때는 다양한 dynamics가 포함되어 있습니다. 이는 특정 악기 혹은 사람의 목소리가 어떻게 “변하는지“를 뜻하는데, 다양한 방식으로 표현할 수 있습니다. 예를 들어, 피아니시모는 매우 작고 조심스럽게 표현하는 방식이고, 포르티시모는 매우 크게 표현하는 방식입니다. 음악에는 슬러, 스타카토, 크레센도 등의 다양한 표현 방식이 존재합니다. 이러한 모든 표현 방식으로 인하여 음악은 감정을 전달하고 교감할 수 있는 하나의 ‘언어‘가 될 수 있습니다.
그 동안 데이터와 오디오 사이에 어떤 일들이 벌어지고 있었는지 살펴봅시다.
데이터의 sonification(음향화)는 최근 핫한 주제이며, 많은 예시를 찾아볼 수 있습니다.
데이터를 시각화할 수 있는 것처럼, 데이터는 들을 수도 있습니다! 위아래로 이동하는 곡선 혹은 색채 패턴으로 음의 높낮이를 표현할 수 있으며, 데이터를 스케일로 표현할 수도 있습니다. 시각화와 비교한다면, 스케일은 graph 의 ‘색깔’로 볼 수 있습니다. 물론 TwoTone과 MIDITime과 같이 데이터를 소리로 변환해주는 프로그램들도 있습니다.
사실 오디오를 데이터로 변환하는 작업은 딥러닝을 통해 엄청난 발전을 이룬 광범위한 연구 분야이기도 합니다.
하지만, 소리와 음악은 다양한 관점에서 서로 다릅니다. 소리를 음악으로 바꾸려면 그 차이를 메꾸는 아이디어와 예술적인 접근이 필요합니다.
오디오가 데이터로 바뀌는 것은 봤지만, 음악도 데이터셋으로 바꿀 수 있습니까?
답은 간단합니다: 네! 하지만 음악의 다른 특징들을 고려하면 더욱 흥미롭습니다.

피아노를 보면 흰색 건반과 검은색 건반이 보입니다. 하지만 이들은 앞서 말한 12 개의 음 중 하나에 불과합니다. 누군가 피아노를 연주한다는 것은 이러한 리드(reed)를 누른다는 것입니다. 컴퓨터에서 작곡할 수 있는 다양한 제작 소프트웨어로 보면, 이런 피아노 리드는 MIDI sequencer 로 볼 수 있으며, ‘piano roll‘이라고 부릅니다.

위의 그림에서 x 축은 마디, y 축은 피아노 리드를 나타내므로, 작은 박스들의 위치를 보면 어떤 음이 어떤 마디에서 연주되었는지 알 수 있습니다.
- piano roll 을 회전하면 이 음악은 간단한 데이터셋으로 변환할 수 있습니다.

각각의 리드들을 칼럼 혹은 feature로 보면 박스들은 이진 값으로 표현할 수 있습니다. 그러면 각각의 음들을 0 또는 1에 대응시킨 데이터셋을 만들 수 있습니다. 데이터셋의 각 행을 관측값으로 보면, 이 경우의 관측값은 마디 혹은 시간이 됩니다.
하지만, 악곡은 다른 특징을 가질 수 있습니다.
예를 들어, 한 음을 얼마나 크게 혹은 부드럽게 연주하는지와 같은 특징이 있습니다. monophonic 음악은 단 하나의 칼럼만 추가하면 dynamic 을 숫자로 표현할 수 있습니다. 0 에서 128 사이의 수로 128이 가장 큰 소리를 뜻합니다.
- monophonic 음악은 바이올린 solo 곡처럼 단선율로만 이루어진 음악을 말한다. 피아노처럼 한 번에 두 개의 음을 동시에 누르는 경우가 있는 음악은 monophonic 음악이 아니라 polyphonic 음악이라고 부른다.
또 아티큘레이션(Articulation)도 있습니다! 음악에는 다양한 아티큘레이션이 사용됩니다. 아티큘레이션은 특정 악기에 한정될 수도 있습니다. 이는 발화(speech)에서의 자음, 모음과 같습니다. 예를 들어, 바이올린은 활을 어떻게 켜느냐에 따라서 같은 음이라도 다르게 들릴 수 있습니다. 하지만 이 또한 monophonic 음악에서는 칼럼 하나를 추가하면 표현할 수 있습니다.
- 아티큘레이션을 칼럼 하나로 표현할 수 있다는 말은 사람이 적당히 categorical하게 분류를 해놓았다는 가정 하에, 해당 음의 아티큘레이션을 그 multi-class 중 하나로 표현할 수 있다는 것을 뜻하는 것으로 보인다. 음을 얼마나 부드럽게 쳤는지, 얼마나 슬프게 쳤는지를 continuous 한 수치로 치환해서 표현하겠다는 의미가 아니다.
- 이제, ‘반짝 반짝 작은 별’을 데이터셋으로 표현한 결과를 봅시다.
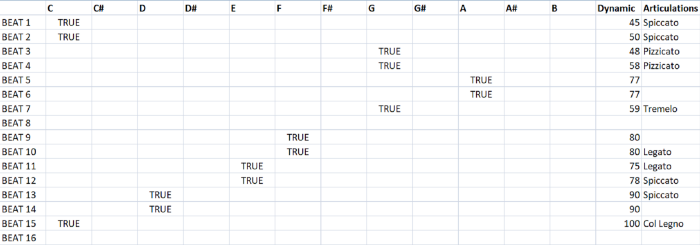
위 데이터셋에서 단일 옥타브의 12 개의 음정이 열(column)이 되고, 각 비트는 행(row)로 표현되었습니다. 또한 각 음의 Dynamic은 바이올리니스트가 연주했다는 가정 하에 Articulation과 결합되어 숫자로 표현되었습니다.
- 지금까지는 음을 표현하는 것이 매우 간단했지만 다음과 같은 경우에는 어려울 수 있습니다.
-
인도 고전 음악 또는 미분음(Microtonal) 음악 : 인도 고전 음악이나 아랍 음악과 같은 미분음 음악에서는 음의 변화에 대한 접근법이 다릅니다. 음은 glides, slides 혹은 ‘Gamaka’와 같은 장식과 함께 연주되는데, 이 경우 이러한 장식과 표기법을 적절하게 포함한 데이터셋을 만드는 것이 다소 까다로울 수 있습니다.
-
Polyphonic 음악 : 여러 악기가 함께 있는 음악보다는 하나의 악기나 목소리만 있는 악곡이 데이터셋으로 바꾸기 쉽습니다. 어떤 경우에는 단일 음성이 여러 옥타브를 차지할 수 있기 때문입니다. 이런 음악을 원곡 그대로 데이터셋으로 만들고 싶다면, 모든 악기/목소리를 포함해야 하고 그러면 상당히 많은 수의 feature 를 가지게 될 것입니다. 이 경우 가장 어려운 점은 ‘시간’을 관측값(row)으로 잡았기 때문에, millisecond 단위가 될 수 있다는 점입니다!
- 대부분의 음악은 Polyphonic 이기에 결국 이 문제는 반드시 해결해야 하고, row 는 이산적으로 쪼갤 수 있도록 시간 단위(ms 혹은 그 이하) 혹은 해당 악곡에 존재하는 가장 작은 비트 단위로 쪼개야 한다.
- 더 다양한 아티큘레이션 : 다양한 악기마다 다채로운 표현과 뉘앙스가 있습니다. 이러한 아티큘레이션을 통해 단순한 ‘음표들의 모음’이 사람이 즐길 수 있는 음악이 됩니다. 문제는 여러 악기가 함께 연주되는 오케스트라 음악을 데이터셋으로 만들 때, 각각의 악기들의 표현을 어떻게 나타낼 것인가 하는 것입니다.

행, 열 그리고…
데이터셋을 행과 열의 구성으로 표현하는 것에서 3D 이상의 차원으로 디자인하도록 변경해야 하는지는 저도 고민입니다. 모든 음들의 아티큘레이션과 dynamics 를 포함해 여러 음성을 가진 악곡을 데이터셋으로 만들기 위해서는 매 시간 구간마다 혹은 매 비트마다 너무나 많은 양의 열이 필요하기 때문입니다. 각각의 음들은 각각의 dynamics 와 아티큘레이션을 가질 수 있습니다. 따라서 동시 발음이 가능한 피아노와 같은 악기나 오케스트라, 앙상블과 같은 경우에는 훨씬 복잡해집니다.
아직 끝이 아닙니다. 사운드 디자인을 기반으로 한 음악 장르도 있습니다. 영화 ‘덩케르크’의 OST ‘Home’처럼 많은 합성 요소가 포함된 음악도 존재하며, 이런 종류의 음악은 어떻게 데이터셋으로 만들어야 하는지에 대한 연구 분야도 많습니다.
악곡을 데이터셋으로 표현했다면 그 다음 뭘 할 수 있을까요? 오디오 인식과 그 구현체는 이미 존재합니다.
무궁무진한 가능성이 있습니다. 음악 데이터셋으로부터 음악과 예술에 대한 세세한 정보를 추출할 수도 있으며, 이는 음악 산업과 그 뒤에 있는 음반사, 아티스트, 프로듀서 및 전문가들에게 새로운 연구의 장을 열어줍니다. 또한 노래의 특정 부분에 대한 청취자들의 반응을 분석하는 데도 사용할 수 있습니다. 더 간단하게는 음악, 음악가, 교감에 관한 미지의 정보를 미래의 누군가가 밝혀주길 기대하고 단순히 음악을 보존하는 용도로도 사용할 수 있습니다.