해당 글은 Jeremy Jordan 의 블로그 포스트 Effective testing for machine learning systems을 번역한 글입니다.
좋은 내용이라 개인 공부할 겸 번역을 진행하였습니다.
단, 한국에서도 영어 단어 자체로 많이 쓰이는 단어들은 굳이 번역하지 않고 그대로 사용하였습니다.
저는 Pytorch Lightining 의 핵심 메인테이너로 일하면서, 소프트웨어 개발 단계에서 테스트가 지니는 가치에 대해 점점 깊은 공감을 하게 되었습니다. 직장에서 새로운 프로젝트를 진행하면서 머신 러닝 시스템을 테스트하는 방법에 대해 상당히 많은 시간을 보냈는데, 몇 주 전 한 동료가 흥미로운 논문을 하나 보내주었습니다. 이 논문으로부터 영감을 얻어 개인적인 생각을 정리한 뒤에 본 포스트를 작성하게 되었습니다.
본 포스트에서는 전통적인 소프트웨어 개발에서의 테스트는 어떠한지, 머신 러닝 시스템을 테스트하는 것과는 무엇이 다른지, 그리고 머신 러닝 시스템을 효과적으로 테스트하기 위한 전략은 어떤 것들이 있는지에 대해 다루겠습니다. 또한, 모델 개발 단계 과정 중 밀접하게 연관된 평가와 테스트의 역할의 차이를 명확히 할 것입니다. 본 포스트를 다 읽은 후에는 여러분이 머신 러닝 시스템을 효과적으로 테스트하는 데 필요한 추가 작업과 그 가치를 모두 확신할 수 있기를 바랍니다.
머신 러닝 시스템을 테스트하는 것이 어떤 점에서 다른가요?
전통적인 소프트웨어 시스템에서 인간은 데이터와 상호 작용하여 원하는 동작을 만들어내는 로직을 작성합니다. 그리고 전통 소프트웨어의 테스트는 작성된 로직이 실제로 기대한 동작을 하는지를 확신하는 데 도움을 줍니다.

하지만 머신 러닝 시스템에서는, 학습하는 동안 인간이 원하는 동작을 예시로 제공하면 모델 최적화 프로세스를 통해 시스템의 로직을 생성합니다. 그렇다면 이 학습된 로직이 계속해서 원하는 동작을 수행한다고 어떻게 확신할 수 있을까요?

먼저 전통적인 소프트웨어 시스템을 테스트하고 고품질 소프트웨어를 개발하는 모범적인 사례부터 살펴보겠습니다.
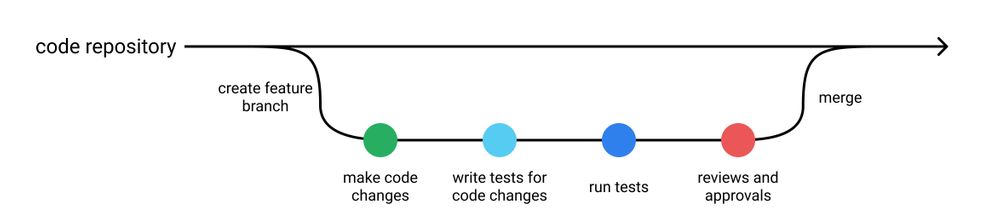
일반적인 소프트웨어 테스트 suite 는 다음을 포함합니다:
- unit test
- 코드 레벨의 작은 단위를 테스트하며, 개발 중에 빠르게 실행할 수 있습니다.
- regression test
- 이전에 발견하고 수정한 버그를 의도적으로 다시 만들어 테스트합니다.
- integration test
- 코드 레벨의 작은 단위들을 통합한 고수준 API 등을 테스트하며, 일반적으로 실행하는 데 오래 걸립니다.
또한, 다음과 같은 컨벤션을 따릅니다:
- 모든 테스트를 통과하기 전까지 merge 하지 않습니다.
- contribute 할 때마다, 새로 작성된 로직에 대한 테스트를 작성합니다.
- 버그 수정 등의 contribution 을 할 때, 버그를 잡아내고 막는 테스트를 작성합니다.
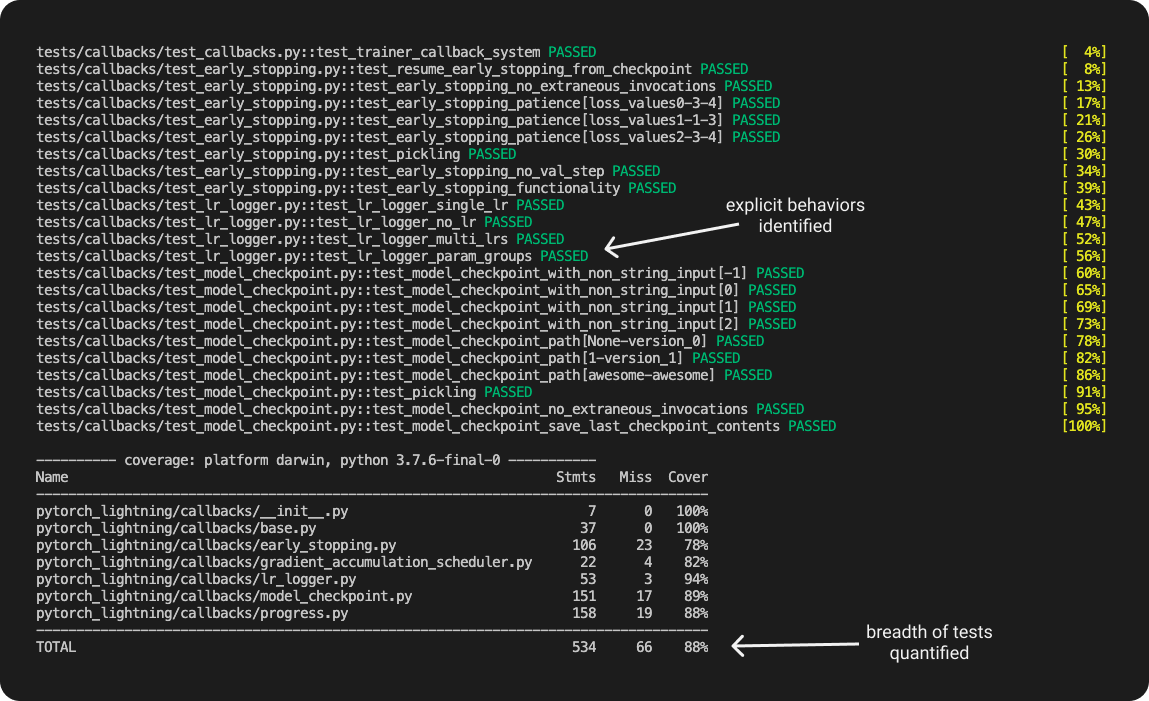
새로 작성된 코드에 대해 테스트 suite 를 실행하면, 테스트를 작성한 특정 동작에 대한 리포트를 받고 변경한 코드가 시스템의 예상 동작에 영향을 미치지 않았는지 확인할 수 있습니다. 어떤 테스트가 실패하면, 어떤 동작이 기대한대로 수행되지 않았는지도 알 수 있습니다. 또한, 테스트 리포트의 코드 커버리지와 같은 평가 지표를 통해 테스트가 얼마나 많은 코드를 커버하는지도 알 수 있습니다.
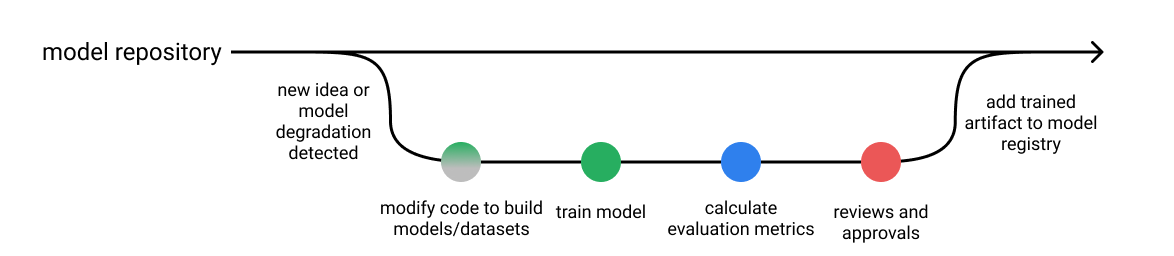
이를 머신 러닝 시스템 개발의 일반적인 workflow 와 비교해보겠습니다. 새로운 모델을 학습하고 나면, 일반적으로 다음과 같은 정보를 포함한 평가 리포트를 생성합니다:
- validation 데이터셋에 대한 특정 메트릭 성능 결과
- Precision-Recall 곡선과 같은 그래프
- 추론 속도와 같은 성능 통계
- 모델이 가장 부정확한 예시
또한, 다음과 같은 컨벤션을 따릅니다:
- 모델 훈련에 사용된 모든 hyper-parameter 를 저장합니다.
- 동일한 데이터셋에 대한 평가를 기준으로 기존 모델(혹은 따로 정해진 기준)에 비해 성능이 향상된 모델만 취합니다.
새로운 머신 러닝 모델을 리뷰할 때, 보통은 validation 데이터셋에 대한 모델 성능을 요약한 메트릭과 그래프를 분석합니다. 우리는 여러 모델의 성능을 서로 비교하고 상대적인 평가를 할 수는 있지만, 특정 모델 하나만을 보고 그 동작을 평가할 수는 없습니다. 예를 들어, 특정 모델이 어디서 실패하는지 알아내려면 추가적인 분석이 필요합니다. 가장 일반적인 방법은 validation 데이터셋에 대해 모델 에러를 심각한 순서대로 살펴보고, 수동으로 분류하는 것입니다.
우리가 만든 모델에 대해 테스트를 직접 작성한다고 하면, (아래에서 다시 언급될 예정이지만) 충분한 테스트가 있는지에 대한 의문이 생길 수 있습니다! 전통적인 소프트웨어 테스트는 코드 커버리지와 같은 메트릭을 사용해 이를 평가할 수 있지만, 단순 코드 라인의 수에서 머신 러닝 모델의 파라미터 수로 어플리케이션 로직이 변경되면 이를 평가하는 것은 굉장히 어려워집니다. 입력 데이터의 분포에 따라 테스트 커버리지를 정량화하는 것이 좋을까요? 아니면 모델 내부의 가능한 activation 에 따라 정량화하는 게 좋을까요?
Odena 의 논문에서는 모든 테스트 예제에 대한 모델 logit 을 계산하고 이런 activation 벡터의 방사형 neighborhood 가 포함하는 영역을 정량화하여 테스트 커버리지 평가에 사용할 수 있는 메트릭을 소개합니다. 하지만, 개인적으로는 산업계에서는 이에 대한 잘 정립된 컨벤션이 아직은 없는 것으로 보입니다. 사실 이런 테스트 커버리지에 대한 질문을 하는 사람이 많이 없는 것으로 보아, 머신 러닝 시스템을 테스트하는 것은 아직은 초기 단계에 머물러있다고 느껴집니다.
모델을 테스트하는 것과 평가하는 것의 차이는 뭔가요?
일반적인 평가 메트릭을 살펴보는 것은 확실히 모델 개발 중의 품질을 보증하는 좋은 방법이지만, 충분하지는 않습니다. 특정 동작에 대한 상세한 리포트가 없다면, 모델을 변경할 경우 동작이 어떻게 변할지 그 뉘앙스를 바로바로 이해할 수 없게 됩니다. 게다가 이전에 발생되었다가 해결된 특정 에러에 대한 동작 회귀를 추적하고 방지할 수도 없습니다.
머신 러닝 시스템에서는 주로 실패가 조용하게 발생하기 때문에 특히 더 위험할 수 있습니다. 예를 들어, 전체 평가 메트릭을 개선시키더라도 특정 데이터 부분집합에 대해서는 regression 이 발생할 수도 있으며, 새로운 데이터셋을 추가하면서 모델에 성별 편향을 추가시켜버릴 수도 있습니다. 이러한 케이스를 확인하기 위해서는 더 미묘한 리포트가 필요한데, 모델을 테스트하는 것이 여기서 큰 역할을 합니다.
머신 러닝 시스템은 모델 평가와 모델 테스트를 병렬적으로 수행해야 합니다.
- 모델 평가(Model evaluation)는 validation 데이터셋과 test 데이터셋에 대한 성능을 요약한 메트릭과 그래프를 포함합니다.
- 모델 테스트(Model testing)는 모델이 예상한대로 동작하는지 명시적으로 확인하는 검사를 포함합니다.
두 관점 모두 좋은 품질의 모델을 만드는 데 중요한 역할을 합니다.
실제로 대부분의 사람들은 자동으로 계산된 평가 메트릭을 확인하고, (실패 모드 분류와 같은)수동 에러 분석으로 일정 수준의 모델 “테스트”를 수행함으로써 두 가지 방법을 조합한 방식을 사용하게 되는데, 머신 러닝 시스템을 위한 모델 테스트를 개발하면 보다 체계적으로 에러 분석을 수행할 수 있습니다.
모델 테스트를 어떻게 작성하나요?
우리가 작성하고 싶은 모델 테스트는 일반적으로 두 부류로 나눌 수 있습니다.
- 사전 학습 테스트(Pre-train test)를 통해 버그를 빠르게 찾아내고 학습을 조기 종료시킬 수 있습니다.
- 사후 학습 테스트(Post-train test)는 학습이 완료된 모델을 사용해서 우리가 정의한 몇 가지 중요한 시나리오의 동작을 분석할 수 있습니다.
사전 학습 테스트
학습이 완료된 파라미터 없이 실행할 수 있는 몇 가지 테스트가 있습니다. 예를 들면 다음과 같습니다:
- 모델 출력값의 shape 이 데이터셋의 label 의 shape 과 일치하는지 확인합니다.
- 출력값의 범위가 예상한 범위 안에 속하는지 확인합니다.
- 예) 분류 모델의 출력값은 클래스별 확률의 합이 1인 분포를 따라야합니다.
- 데이터 batch 에 대한 gradient step 를 1 번 수행하면 loss 가 줄어드는지 확인합니다.
- 데이터셋에 대한 검증을 진행합니다.
- 학습 데이터셋과 validation 데이터셋 사이에 label leakage 가 없는지 확인합니다.
이러한 테스트의 주요 목적은 잘못된 학습을 수행하는 시간 낭비를 하지 않도록 에러를 조기에 파악하는 것입니다.
사후 학습 테스트
그러나 모델이 어떻게 동작하는지 이해하려면 학습이 완료된 모델 아티팩트를 테스트해야 합니다. 이러한 테스트는 학습 단계에서 학습한 로직을 상세히 조사하고 모델의 동작에 대한 성능 리포트를 제공하는 것을 목표로 합니다.
위 논문에서 저자는 모델의 동작에 대한 특징을 이해하는 데 사용할 수 있는 모델 테스트 세 가지를 소개합니다.
Invariance Tests
불변성 테스트(Invariance Test)를 통해 모델의 출력에는 영향을 주지 않고 입력에 적용할 수 있는 일련의 작은 변화들(perturbation)을 설명할 수 있습니다. 이러한 작은 변화들을 사용하여 입력 샘플의 쌍(원본 vs 변형)을 준비하고 이를 사용해 모델 예측의 일관성을 검증할 수 있습니다. 이는 학습 시 data 를 사용할 때, 원본 label 을 보존하되 input 을 변형시키는 개념인 data augmentation 과 밀접하다고 볼 수 있습니다.
예를 들어, 다음 두 문장의 감성 분석 모델을 실행한다고 상상해봅시다:
- Mark 는 훌륭한 강사였습니다.
- Samantha 는 훌륭한 강사였습니다.
단순히 대상 이름을 변경하는 것은 모델 예측에 영향을 주지 않을 것이라는 것을 충분히 예상할 수 있습니다.
Directional Expectation Tests
반면, 방향성 기대 테스트(Directional Expectation Test)를 통해 모델의 출력 결과에 예상된 영향을 미치는 일련의 작은 변화들을 정의할 수 있습니다.
예를 들어, 주택 가격 예측 모델의 경우 다음과 같이 주장할 수 있습니다:
- (다른 모든 변수를 고정시키고) 욕실의 수를 늘리면 가격이 하락해서는 안됩니다.
- (다른 모든 변수를 고정시키고) 집의 면적을 줄이면 가격이 증가해서는 안됩니다.
모델이 두 번째 테스트에서 실패하는 다음과 같은 시나리오를 가정해보겠습니다. validation 데이터셋에서 임의의 row 하나를 가져와서 house_sq_ft라는 변수를 줄이면 원래 label 보다 더 높은 가격을 예측하는 경우를 발견했다고 합시다. 이는 우리의 직관에 어긋나는 놀라운 결과이기 때문에, 이런 결과가 나온 이유를 자세히 분석해보았습니다. 분석해보니 우리의 모델은 집의 이웃과 위치 변수에 대한 값이 없는 경우에는 작은 면적이 더 비싸다고 학습한 것을 발견하게 되었습니다. 추가로 이렇게 학습하게 된 원인은 학습 데이터셋에서 작은 면적의 집이 주로 가격이 비싼 도시에 분포되어 있었기 때문이라는 것도 알게 되었습니다.
이처럼 학습 데이터셋의 선택이 우리가 의도하지 않은 방향으로 모델의 로직에 영향을 미칠 수 있습니다. 이러한 케이스는 단순히 validation 데이터셋에서의 모델 성능을 평가하는 것만으로는 절대 알아낼 수 없는 결과입니다.
Minimum Functionality Tests (a.k.a. data unit tests)
전통 소프트웨어의 단위 테스트가 코드 레벨에서 단위 컴포넌트를 분리하고 테스트하는 걸 목표로 하는 것처럼 데이터 단위 테스트(data unit test)도 데이터의 특정 케이스에 대한 모델 성능을 정량화할 수 있게 해줍니다.
이를 통해 예측 오류가 높은 결과를 이끌어내는 중요한 시나리오를 판단할 수 있습니다. 또한 오류 분석 중에 실패 케이스를 발견하면 이에 대한 데이터 단위 테스트를 작성할 수도 있습니다. 이러한 작업을 통해서 다음 버전의 모델에서 에러를 찾는 것을 “자동화”할 수 있게 됩니다.
Snorkel 은 Slicing 함수을 통해 비슷한 접근 방법을 소개하였습니다. 이는 주어진 데이터셋에서 특정 기준을 만족하는 부분집합을 찾아내는 실용적인 함수입니다. 예를 들어서, Slicing 함수를 사용해서 5 단어 미만으로 이루어진 문장 데이터를 추출한 뒤, 이러한 데이터에 대해서 모델이 어떻게 작동하는지 평가할 수 있습니다.
테스트 구성하기
전통적인 소프트웨어 테스트에서는 보통 소스코드 저장소의 구조를 따라 테스트를 구성합니다. 하지만, 머신 러닝 모델의 로직은 paramter 에 의해 구조화되기 때문에 이러한 방식은 적합하지 않습니다.
위에 링크된 체크리스트 논문의 저자들은 모델이 학습할 것으로 예상되는 “스킬”에 따라 테스트를 구성할 것을 추천합니다.
예를 들어, 감성 분석 모델의 경우 다음과 같은 “스킬”을 학습할 것으로 예상할 수 있습니다:
- 어휘와 품사
- 노이즈에 대한 견고성
- named entity 식별
- 일시적 관계
- 단어의 부정
이미지 인식 모델의 경우에는 다음과 같은 “스킬”을 학습할 것으로 예상할 수 있습니다:
- 개체 회전
- 부분 폐색
- 원근 전환
- 명암 조건
- 날씨 관련 아티팩트 (비, 눈, 안개 등)
- 카메라 관련 아티팩트 (ISO 노이즈, 모션 블러)
모델 개발 파이프라인
위 모든 내용을 종합하면, 학습 전 후 테스트를 포함하도록 모델 개발 과정 그림을 수정할 수 있습니다. 모델 평가 리포트와 더불어 이러한 테스트 결과도 함께 활용하여 모델을 검토할 수 있도록 파이프라인의 마지막 단계에서 표시합니다. 모델 학습의 특성에 따라 특정 기준을 만족하는 모델을 자동으로 승인하도록 설정할 수도 있습니다.
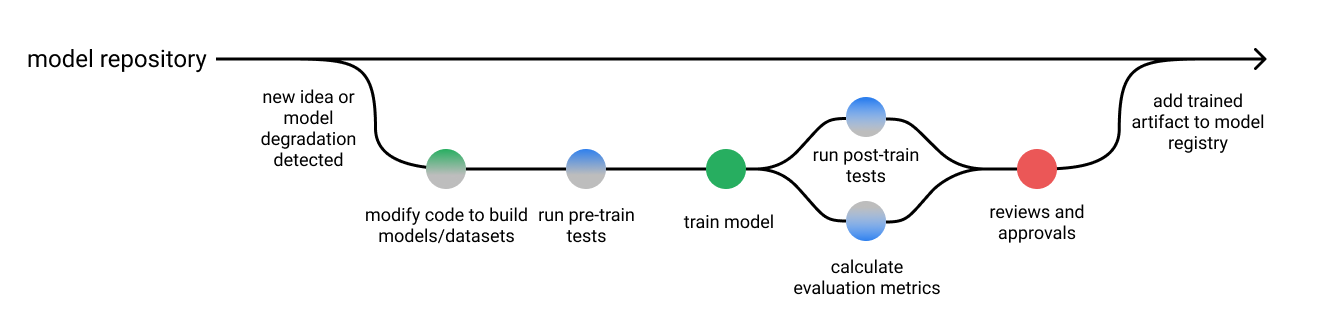
결론
머신 러닝 시스템은 시스템의 로직을 명시적으로 작성하지 않고 학습하기 때문에 테스트하기 더 까다롭습니다. 하지만, 테스트 자동화는 좋은 품질의 소프트웨어 시스템을 위해서는 굉장히 중요한 부분입니다. 이러한 테스트를 통해 얻은 학습 모델 동작 리포트를 통해서 오류 분석을 보다 체계적으로 접근할 수 있게 됩니다.
본 포스트에서는 “전통 소프트웨어 개발”과 “머신 러닝 모델 개발”을 두 가지 다른 개념으로 설명했습니다. 이러한 단순화를 통해 머신 러닝 시스템을 테스트하는 것과 연관된 고유한 문제들을 쉽게 설명할 수 있었습니다. 하지만, 현실 세계는 훨씬 지저분합니다. 머신 러닝 모델을 개발하는 것은 “전통 소프트웨어 개발”에 많은 부분을 의존하고 있습니다. 입력 데이터 처리, 변수 표현 생성, data augmentation 수행, 모델 학습 관리, 외부 시스템에 대한 인터페이스 노출 등이 “전통 소프트웨어 개발” 영역에 속합니다. 따라서, 머신 러닝 시스템의 효과적인 테스트는 전통 소프트웨어 테스트 suite(모델 개발 인프라 측면) 와 모델 테스트 suite(학습된 모델 측면) 둘 모두 요구합니다.
여러분도 머신 러닝 시스템을 테스트한 경험이 있으시다면, 배운 내용을 공유해주세요!
이 게시물을 작성하도록 영감을 준 논문을 보내 주신 Xinxin Wu에게 감사드립니다! 또한 이 게시물의 초기 초안을 읽고 유용한 피드백을 제공해 주신 John Huffman, Josh Tobin 및 Andrew Knight 에게 감사드립니다.
Further Reading
Papers
- Beyond Accuracy: Behavioral Testing of NLP Models with CheckList
- TensorFuzz: Debugging Neural Networks with Coverage-Guided Fuzzing
Blog posts
Talks (nice introductions to testing for data scientists)
Code